Chapter 9 R 고급 데이터 변환
7 장과 8 장에서 정돈 형식의 데이터를 변환하고 시각화하는 방법을 배웠다. 그러나 실제 데이터 분석에서는 분석하고자 하는 데이터가 하나의 데이터 프레임에 정돈 형식으로 제공되는 경우가 많지 않다. 대부분의 경우 다음 두 가지 작업 중 하나 또는 두 가지 모두가 필요한 경우가 많다.
- [Merge] 다양한 원천에서 획득된 데이터를 하나의 정돈 형식의 데이터로 결합하기
- [Reshape] 비정돈 형식의 데이터를 정돈 데이터 형식으로 변형하기
본 장에서는 이러한 데이터 전처리에 필요한 다양한 기법을 논의한다.
데이터의 결합을 위해서는 dplyr 패키지를 사용할 것이며, 비정돈 형식의 데이터를 정돈 데이터 형식으로 변형하기 위해서는 tidyr 패키지를 사용할 것이다. 이 두 패키지는 모두 tidyverse 패키지에 속해 있으므로, 이 두 패키지를 사용하기 위해서 tidyverse 패키지를 적재한다.
9.1 데이터의 단순 결합
행으로 결합 vs. 열로 결합
데이터에 대한 결합이 필요한 다음 두 가지 상황을 고려해 보자.
데이터가 동일한 열 형식으로 여러 파일로 나뉘어져 있는 경우: 예를 들어 판매 실적 데이터가 2021년 데이터는 2021.csv 파일에 2022년 데이터는 2022.csv 파일에 있다고 가정해 보자. 이 경우 각 파일을 별도의 데이터 프레임으로 읽어들인 후 행으로 결합시켜야 할 것이다.
데이터가 동일한 행으로 되어 있으나, 서로 다른 열을 가지고 있는 경우: 예를 들어 사원 번호 순으로 한 파일에는 입사시점의 개인 정보가, 다른 파일에는 작년 인사 평가 결과 데이터가 있다고 하자. 두 파일에 동일한 사원 번호 순으로 데이터가 기록되어 있다면 두 파일의 정보를 데이터 프레임으로 읽어들인 후 열로 결합하여야 할 것이다.
데이터 프레임을 행과 열로 결합하는 작업은 6 장에서 소개한 R의 기본 함수인 rbind()와 cbind()를 사용하여도 수행할 수 있다. 그러나 여기에서는 dplyr 패키지의 bind_rows()와 bind_cols() 함수를 사용하여 여러 데이터 프레임을 행과 열로 결합할 것이다.
bind_rows()와 bind_cols() 함수를 사용하는 이유는 이 두 함수가 R의 기본 함수보다 처리 속도가 빠를 뿐 아니라, R의 기본 함수보다는 편리한 기능을 가지고 있기 때문이다.
9.1.1 데이터를 행으로 결합하기
열 구조가 다른 데이터를 행으로 결합하기
데이터를 행으로 결합하는 작업이 필요한 경우, 데이터가 동일한 열 구조를 가지고 있지 않은 경우가 종종 발생한다. 동일한 열을 가지고 있더라도 열 이름이 서로 다른 경우도 있다. 이런 경우에는 결합하려는 데이터 프레임을 동일한 열 구조로 변형하여 결합하여야 한다.
앞으로의 예제들은 다음 파일에 포함된 데이터를 사용하니 예제를 따라하고자 하는 분들은 내려받기를 하자.
Download advancedDataMgmt.RData내려받은 파일을 우클릭하여 RStudio로 열거나 내려받은 파일이 있는 폴더를 작업디렉토리로 설정한 후 다음 명령을 수행하면 class1과 class2 등의 데이터가 적재된다. 이 데이터는 대학의 어떤 강의의 두 분반의 중간 및 기말 고사 정보이다.
ID Name Gender Year Address Midterm Final Team
1 15 김철수 M 1 서울 78 59 A
2 18 김영희 F 3 경기 85 87 A
3 25 이철수 M 3 충남 80 70 B
4 34 이영희 F 2 대전 92 89 B
5 151 홍길동 Male 4 세종 58 66 B ID Mid Final Name Team Gen Year
1 12 75 79 장철수 C M 2
2 19 75 89 장영희 C F 2
3 28 87 76 최철수 D M 1
4 45 82 79 최영희 D F 30두 데이터 모두 학번(ID), 중간고사(Midterm), 기말고사(Final), 프로젝트 팀(Team), 성별(Gender), 학년(Year)에 대한 정보를 포함하고 있으나, class1에는 학생의 주소(Address) 열이 포함되어 있고 class2는 그렇지 않다. 또한 두 데이터의 열의 위치와 이름도 조금 다르다.
rbind()는 열의 개수가 다른 데이터 프레임을 행으로 결합하지 못한다.
두 분반 학생의 점수를 통합하여 성적 처리를 하기 위해 두 분반의 데이터를 결합하려고 한다고 하자. 이를 어떻게 수행하여야 할까? rbind()로 먼저 두 데이터 프레임을 통합하려고 시도해 보자.
Error in rbind(deparse.level, ...): numbers of columns of arguments do not match열의 수가 다르기 때문에 결합이 되지 않음을 알 수 있다. 따라서 rbind()로 두 데이터를 결합하려면 class1에만 있는 Address 열을 어떻게 처리할지를 결정해야 한다. 일반적으로 다음 둘 중 하나의 방법을 택하여 문제를 해결한다. 첫번째 방법은 class1의 Address 열을 제외하고 결합하는 것이고, 두번째 방법은 class2에 Address 열을 추가하고 결측치(NA)로 값을 준 후 결합하는 것이다.
bind_rows()는 열의 개수가 다른 데이터 프레임임도 행으로 결합을 한다.
두 분반 학생의 데이터를 dplyr 패키지의 bind_rows() 함수를 사용하여 연결해 보자.
ID Name Gender Year Address Midterm Final Team Mid Gen
1 15 김철수 M 1 서울 78 59 A NA <NA>
2 18 김영희 F 3 경기 85 87 A NA <NA>
3 25 이철수 M 3 충남 80 70 B NA <NA>
4 34 이영희 F 2 대전 92 89 B NA <NA>
5 151 홍길동 Male 4 세종 58 66 B NA <NA>
6 12 장철수 <NA> 2 <NA> NA 79 C 75 M
7 19 장영희 <NA> 2 <NA> NA 89 C 75 F
8 28 최철수 <NA> 1 <NA> NA 76 D 87 M
9 45 최영희 <NA> 30 <NA> NA 79 D 82 F열의 개수가 달라도 결합이 이루어지는 것을 볼 수 있다. 두 데이터에서 서로 없는 열은 결측치 NA로 처리되어 결합이 이루어지는 것을 볼 수 있다. 그러나 사실 class1의 Midterm과 class2의 Mid는 중간고사 점수 열로 같은 정보가 다른 열 이름으로 표현된 것 뿐이다. bind_rows()는 이름이 다르면 서로 다른 열이라고 생각하여 각각 새로운 열을 만들어 결합을 한다. 그러므로 사실상 같은 열이 서로 다른 이름으로 되어 있다면 이름을 동일하게 바꾸어 주어서 결합을 하여야 한다.
rbind()는 두 데이터의 열의 이름이 다른 경우 행으로 결합하지 못한다.
class1 데이터의 Address 열을 제외하고 두 데이터를 다시 rbind()로 결합해 보자.
Error in match.names(clabs, names(xi)): 이전에 사용된 이름들과 일치하지 않습니다.rbind()는 열의 개수가 동일하더라도 두 데이터 프레임의 열의 이름이 서로 다르면 행으로 결합하지 못함을 볼 수 있다. 지금 중간고사 점수 열과 성별 열의 이름이 서로 다르기 때문에 연결이 안되는 것이므로 다음처럼 열의 이름을 변경한 후 두 데이터 프레임을 행으로 연결시킨다.
ID Name Gender Year Midterm Final Team
1 15 김철수 M 1 78 59 A
2 18 김영희 F 3 85 87 A
3 25 이철수 M 3 80 70 B
4 34 이영희 F 2 92 89 B
5 151 홍길동 Male 4 58 66 B
6 12 장철수 M 2 75 79 C
7 19 장영희 F 2 75 89 C
8 28 최철수 M 1 87 76 D
9 45 최영희 F 30 82 79 Drbind()와 bind_rows()는 열의 순서를 자동으로 맞춘다.
이제 두 데이터 프레임의 열의 형태가 같아졌으므로 bind_rows()로 두 데이터를 원하는 방식으로 합칠 수 있다.
두 데이터 프레임의 열의 순서가 다른 경우 rbind()와 bind_rows()는 첫번째 데이터 프레임의 열 이름을 기준으로 열의 순서를 자동으로 맞추어 준다.
ID Name Gender Year Midterm Final Team
1 15 김철수 M 1 78 59 A
2 18 김영희 F 3 85 87 A
3 25 이철수 M 3 80 70 B
4 34 이영희 F 2 92 89 B
5 151 홍길동 Male 4 58 66 B
6 12 장철수 M 2 75 79 C
7 19 장영희 F 2 75 89 C
8 28 최철수 M 1 87 76 D
9 45 최영희 F 30 82 79 D합쳐지는 데이터에 식별자 부여하기
앞의 class1과 class2 데이터는 1분반과 2분반 학생의 데이터이다. 그런데 이 두 데이터를 행으로 결합한 데이터에서는 각 행이 어떤 데이터에서 온 것인지에 대한 정보가 없기 때문에 학생이 속한 분반을 확인할 수 없다.
이런 경우 bind_rows()의 .id 인수를 사용하면, 결합되는 데이터의 순서에 따라 일련번호를 부여하는 열을 생성할 수 있다.
bind_rows(select(class1, -Address),
rename(class2, Midterm = Mid, Gender = Gen),
.id = "Class") # class 열로 데이터 출처 식별 Class ID Name Gender Year Midterm Final Team
1 1 15 김철수 M 1 78 59 A
2 1 18 김영희 F 3 85 87 A
3 1 25 이철수 M 3 80 70 B
4 1 34 이영희 F 2 92 89 B
5 1 151 홍길동 Male 4 58 66 B
6 2 12 장철수 M 2 75 79 C
7 2 19 장영희 F 2 75 89 C
8 2 28 최철수 M 1 87 76 D
9 2 45 최영희 F 30 82 79 Dbind_rows()에 두 개 이상의 데이터프레임으로 구성된 리스트를 제공하여도 데이터프레임을 행으로 잘 결합한다.
ID Name Gender Year Midterm Final Team
1 15 김철수 M 1 78 59 A
2 18 김영희 F 3 85 87 A
3 25 이철수 M 3 80 70 B
4 34 이영희 F 2 92 89 B
5 151 홍길동 Male 4 58 66 B
6 12 장철수 M 2 75 79 C
7 19 장영희 F 2 75 89 C
8 28 최철수 M 1 87 76 D
9 45 최영희 F 30 82 79 D리스트의 요소인 데이터프레임에 이름을 부여하면 .id 인수로 만든 열이 생성될 때 이름을 사용한다.
dfs = list(cls1=select(class1, -Address), cls2=rename(class2, Midterm = Mid, Gender = Gen))
bind_rows(dfs, .id="Class") Class ID Name Gender Year Midterm Final Team
1 cls1 15 김철수 M 1 78 59 A
2 cls1 18 김영희 F 3 85 87 A
3 cls1 25 이철수 M 3 80 70 B
4 cls1 34 이영희 F 2 92 89 B
5 cls1 151 홍길동 Male 4 58 66 B
6 cls2 12 장철수 M 2 75 79 C
7 cls2 19 장영희 F 2 75 89 C
8 cls2 28 최철수 M 1 87 76 D
9 cls2 45 최영희 F 30 82 79 D실제 데이터를 행으로 결합하는 과정에는 훨씬 더 다양한 문제들이 발생한다. 예를 들어 동일한 키를 나타내는 열이 하나는 cm로 하나는 m 단위로 정보가 주어져 있으면 이를 하나의 단위로 통일해야 한다. 그러나 복잡한 문제들도 결국 서로 다른 열 구조를 행으로 결합하기 위해서 어떤 열을 추가하거나 제외할 것인지를 결정하고, 열의 형식과 이름을 어떻게 통일할 것인가를 고려하는 과정이라는 점에서 본질적으로는 앞의 예와 동일하다 할 수 있다.
9.1.2 데이터를 열로 결합하기
행 순서가 다른 데이터를 열로 결합하기
데이터를 열로 결합하는 경우 실제 데이터가 동일한 행 순서로 정렬되어 있지 않은 경우가 종종 있다. 예를 들어 앞의 예에서 성적 처리를 위해서는 학생의 중간, 기말 고사 점수와 함께 출석 점수를 고려해야 한다고 하자. 그리고 출석점수는 attendance 데이터 프레임에 다음과 같이 class1과 class2의 모든 학생의 학번(ID) 순으로 정렬되어 분반 정보(Class)와 출석 점수(Attend)가 저장되어 있다고 하자.
ID Class Attend
1 12 2 185
2 15 1 90
3 18 1 95
4 19 2 100
5 25 1 100
6 28 2 100
7 34 1 100
8 45 2 100
9 151 1 95앞서 두 분반의 중간 및 기말 고사 데이터가 합쳐진 class12는 학번이 기준이 아니라 분반으로 정렬되어 있다. 따라서 이 두 데이터 프레임을 단순하게 열로 결합하면 출석점수가 엉뚱한 학생에게 부여된다.
정렬 후 열로 결합하기
이를 해결하는 가장 간단한 방법은 두 데이터 프레임을 동일한 기준으로 정렬한 후 cbind()나 bind_cols()를 수행하는 것이다.
먼저 class12를 ID 순으로 정렬한 후 열로 결합해 보자.
그런데 ID 열은 두 데이터 프레임에 모두 있으므로 하나는 불필요하다. 따라서 attendance 데이터 프레임의 ID 열을 제거한 후 결합한다.
ID Name Gender Year Midterm Final Team Class Attend
1 12 장철수 M 2 75 79 C 2 185
2 15 김철수 M 1 78 59 A 1 90
3 18 김영희 F 3 85 87 A 1 95
4 19 장영희 F 2 75 89 C 2 100
5 25 이철수 M 3 80 70 B 1 100
6 28 최철수 M 1 87 76 D 2 100
7 34 이영희 F 2 92 89 B 1 100
8 45 최영희 F 30 82 79 D 2 100
9 151 홍길동 Male 4 58 66 B 1 95다른 방법으로 attendance 데이터 프레임을 Class와 ID 열로 정렬한 후 class12 데이터 프레임과 결합할 수도 있다. attendence 데이터를 분반과 학번으로 정렬하여 class112와 순서를 맞춘 후 데이터를 열로 결합해 보자.
ID Name Gender Year Midterm Final Team Class Attend
1 15 김철수 M 1 78 59 A 1 90
2 18 김영희 F 3 85 87 A 1 95
3 25 이철수 M 3 80 70 B 1 100
4 34 이영희 F 2 92 89 B 1 100
5 151 홍길동 Male 4 58 66 B 1 95
6 12 장철수 M 2 75 79 C 2 185
7 19 장영희 F 2 75 89 C 2 100
8 28 최철수 M 1 87 76 D 2 100
9 45 최영희 F 30 82 79 D 2 100실제 데이터는 이보다 더 복잡한 문제를 가지고 있는 경우가 많다. 예를 들어 한 파일에 있는 행이 다른 파일에는 없는 경우도 있다. 이러한 경우엔 그 행의 정보를 모두 제거할 것인지, 아니면 그 행에 대해 없는 정보는 NA로 하여 결합을 할지 결정해야 한다. 결국 cbind()나 bind_rows()를 이용하여 열로 결합하기 위해서는 두 데이터의 행이 동일한 개체에 대한 정보가 되도록 일치시키는 것이 중요하다. 그런데 매번 두 데이터가 동일한 행으로 결합되도록 정렬하여 결합하는 작업을 사용자가 직접 하는 것은 오류 발생 가능성이 많다. 따라서 이 작업은 다음에 소개하는 ’관계형 데이터베이스처럼 데이터 결합하기’에 소개하는 방법을 사용할 것을 권장한다.
9.2 관계형 데이터베이스처럼 데이터 결합하기
관계형 데이터베이스에서는 서로 다른 열 정보를 담고 있는 두 데이터 테이블을 key를 사용하여 join이라는 방식을 이용하여 연결시킨다. 여기서 key란 앞서 성적 데이터와 출석 데이터에서 특정 학생 정보임을 식별할 수 있는 학번(ID) 등을 말한다.
R에서도 두 데이터 프레임을 관계형 데이터베이스의 join과 같은 방식으로 결합시킬 수 있다. 이 작업은 R의 기본 함수인 merge() 함수를 이용하여 수행할 수도 있고, dplyr 패키지의 join 함수들을 사용하여 수행할 수도 있다. 이 책에서는 dplyr의 join 함수들을 이용하여 관계형 데이터베이스처럼 결합하기를 수행하는 방법을 설명하도록 한다.
9.2.1 Inner join과 outer join
앞의 예에서 우리는 중간, 기말 고사 점수를 가지고 있는 class12 데이터 프레임과 출석 점수를 가지고 있는 attendance 데이터 프레임을 합치기 위해 ID 열로 데이터 프레임을 정렬한 후 bind_cols()로 연결하였다. 이 작업은 dplyr의 inner_join() 함수를 이용하면 더 손쉽게 수행할 수 있다.
inner_join()
inner_join() 함수는 결합할 두 데이터 프레임을 인수로 먼저 기술한 다음 by 인수에 어떤 열을 기준으로 결합할 것인지를 열 이름으로 기술한다. inner_join() 함수는 두 데이터 프레임에서 by 인수로 주어진 열의 값이 동일한 행을 서로 연결하여 새로운 데이터 프레임을 만든다. 또한 새로 만들어진 데이터 프레임은 by 열을 기준으로 정렬이 이루어진다.
ID Name Gender Year Midterm Final Team Class Attend
1 15 김철수 M 1 78 59 A 1 90
2 18 김영희 F 3 85 87 A 1 95
3 25 이철수 M 3 80 70 B 1 100
4 34 이영희 F 2 92 89 B 1 100
5 151 홍길동 Male 4 58 66 B 1 95
6 12 장철수 M 2 75 79 C 2 185
7 19 장영희 F 2 75 89 C 2 100
8 28 최철수 M 1 87 76 D 2 100
9 45 최영희 F 30 82 79 D 2 100- 만약 두 데이터 프레임이 결합의 기준이 되는 열의 이름이 다르면 `by = c(“key.x” = “key.y”) 형식으로 두 데이터 프레임의 키 열의 이름을 기술하여 결합하면 된다.
- 만약 결합의 기준이 되는 열이 두 개 이상이면 `by = c(“key1”, “key2”) 형식으로 기술한다.
- 만약 결합의 기준이 되는 열이 두 개 이상이고 서로 이름이 다르면
by = c("key1.x" = "key1.y", "key2.x" = "key2.y")형식으로 두 데이터 프레임의 키 열의 이름을 기술한다. 관련 정보는inner_join()함수의 도움말을 참조하라.
1:1 inner join
앞의 예처럼 데이터가 결합되는 방식을 1 대 1 inner join이라고 부른다. 두 데이터 프레임에 ID가 동일한 학생은 오직 한 명만 존재하고, 두 데이터 프레임의 학생의 ID가 일 대 일로 대응된다. 따라서 두 데이터 프레임의 행들이 일 대 일로 결합되어 새로운 데이터 프레임이 생성된다.
by 인수가 주어지지 않으면 inner_join() 함수는 두 데이터 프레임에서 이름이 같은 열을 찾고 그 열을 기준으로 결합을 한다. 따라서 위의 경우 by 인수를 설정하지 않으면, 두 데이터 프레임에 공통으로 있는 ID 열을 기준으로 데이터가 결합된다.
Joining with `by = join_by(ID)` ID Name Gender Year Midterm Final Team Class Attend
1 15 김철수 M 1 78 59 A 1 90
2 18 김영희 F 3 85 87 A 1 95
3 25 이철수 M 3 80 70 B 1 100
4 34 이영희 F 2 92 89 B 1 100
5 151 홍길동 Male 4 58 66 B 1 95
6 12 장철수 M 2 75 79 C 2 185
7 19 장영희 F 2 75 89 C 2 100
8 28 최철수 M 1 87 76 D 2 100
9 45 최영희 F 30 82 79 D 2 1000:1 inner join
앞서 inner_join() 함수는 두 데이터 프레임에서 by 인수로 주어진 열의 값이 같은 행을 서로 연결한다고 했다. 그러면 한 데이터 프레임에는 해당 개체의 정보가 있으나 다른 데이터 프레임에는 해당 개체의 정보가 없는 경우에 두 데이터 프레임을 연결하면 어떻게 될까?
다음 예처럼 class1에는 1분반 학생의 데이터만 있고, attendance는 1, 2분반의 학생 데이터가 모두 있는 경우 두 데이터 프레임을 ID 열로 결합하는 경우를 고려해 보자. attendance에는 동일한 ID를 가지고 있는 학생이 오직 한 명만 존재하고, class1에는 attendance에 있는 학생 정보가 0개 또는 1개가 있는 경우이다. 이러한 데이터 결합 방식을 0 대 1 inner join이라고 부른다.
Inner join은 두 데이터 프레임에서 by로 지정된 열이 값이 서로 대응이 되는 행만 남겨둔다. 따라서 위의 경우에는 class1에 있는 학생의 행으로만 구성된 데이터 프레임이 생성된다. 즉, by 인수에 주어진 열이 서로 동일한 값을 가진 행만 결합되어 결과가 나오므로 한 쪽 데이터 프레임에 없는 행은 제거되었음을 알 수 있다.
ID Name Gender Year Address Midterm Final Team Class Attend
1 15 김철수 M 1 서울 78 59 A 1 90
2 18 김영희 F 3 경기 85 87 A 1 95
3 25 이철수 M 3 충남 80 70 B 1 100
4 34 이영희 F 2 대전 92 89 B 1 100
5 151 홍길동 Male 4 세종 58 66 B 1 95outer join
한 쪽 데이터 프레임에 해당 행이 없더라도 어느 한쪽의 데이터 프레임에 행이 있으면 그 행을 포함시킬 필요가 있는 경우가 있다. 예를 들어 앞의 예에서 2분반의 중간 및 기말 고사 정보가 나중에 획득되면 추후 보강하기로 하고 현재 출석 점수가 있는 모든 학생의 정보가 나오도록 중간과 기말 점수와 출석 데이터를 결합한다고 하자.
이러한 경우 outer_join 함수들을 사용한다. Outer join 함수는 다음 세 가지가 있다.
left_join(x, y): x에 있는 행을 모두 유지하여 join을 수행한다.right_join(x, y): y에 있는 행을 모두 유지하여 join을 수행한다.full_join(x, y): x와 y의 모든 행을 유지하여 join을 수행한다.
대신 한 쪽에 없는 정보는 모두 결측치 NA가 입력되어 결합된다.
다음은 inner_join(), left_join(), right_join(), full_join()의 차이가 무엇인지를 보여주는 예이다.
id name
1 1 a
2 2 b
3 3 c id addr
1 2 B
2 3 C
3 4 DJoining with `by = join_by(id)` id name addr
1 2 b B
2 3 c CJoining with `by = join_by(id)` id name addr
1 1 a <NA>
2 2 b B
3 3 c CJoining with `by = join_by(id)` id name addr
1 2 b B
2 3 c C
3 4 <NA> DJoining with `by = join_by(id)` id name addr
1 1 a <NA>
2 2 b B
3 3 c C
4 4 <NA> D다음은 class1과 attendance 데이터에서 attendance의 모든 행을 남겨두는 outer join을 수행한 결과이다.
ID Name Gender Year Address Midterm Final Team Class Attend
1 15 김철수 M 1 서울 78 59 A 1 90
2 18 김영희 F 3 경기 85 87 A 1 95
3 25 이철수 M 3 충남 80 70 B 1 100
4 34 이영희 F 2 대전 92 89 B 1 100
5 151 홍길동 Male 4 세종 58 66 B 1 95
6 12 <NA> <NA> NA <NA> NA NA <NA> 2 185
7 19 <NA> <NA> NA <NA> NA NA <NA> 2 100
8 28 <NA> <NA> NA <NA> NA NA <NA> 2 100
9 45 <NA> <NA> NA <NA> NA NA <NA> 2 1001:n inner join
만약에 한 데이터 프레임에서 결합의 기준이 되는 열에 동일한 값이 여러번 나오면 어떻게 될까? 다음의 예를 살펴보면서 그 결과가 어떻게 되는지 확인해 보자.
지금까지 우리는 class12.a라는 데이터 프레임에 중간, 기말, 출석 점수를 통합하였다. 그런데 다음과 같이 프로젝트 팀별로 프로젝트 평가 점수가 있다고 하자.
Team Project
1 A 80
2 B 90
3 C 85
4 D 75한 프로젝트 팀에는 2, 3 명의 학생이 포함되고, 프로젝트 점수는 프로젝트 팀별로 주어지고 학생 개별로는 부여되지 않는다. 따라서 학생의 성적을 산정하려면 각 학생이 어떤 프로젝트 팀에 속한지를 확인한 후 학생이 속한 프로젝트 팀의 점수를 그 학생의 프로젝트 점수로 부여하는 작업이 필요하다.
이 경우 class12.a와 pjt 데이터 프레임이 결합되어야 하는데, 결합의 기준 열은 프로젝트 팀을 나타내는 Team 열이 되어야 한다. 그런데 pjt 데이터 프레임에는 한 팀에 해당되는 행이 오직 한 개만 존재하지만, class12.a 데이터 프레임에는 한 팀에 속한 학생이 여러 명 있으므로 여러 행이 존재한다. 이러한 경우의 데이터 결합 방식을 1 대 n inner join이라고 한다.
다음은 inner_join()를 사용하여 n 대 1의 관계의 두 데이터 프레임을 inner join 한 결과이다.
ID Name Gender Year Midterm Final Team Class Attend Project
1 12 장철수 M 2 75 79 C 2 185 85
2 15 김철수 M 1 78 59 A 1 90 80
3 18 김영희 F 3 85 87 A 1 95 80
4 19 장영희 F 2 75 89 C 2 100 85
5 25 이철수 M 3 80 70 B 1 100 90
6 28 최철수 M 1 87 76 D 2 100 75
7 34 이영희 F 2 92 89 B 1 100 90
8 45 최영희 F 30 82 79 D 2 100 75
9 151 홍길동 Male 4 58 66 B 1 95 90결과에서 보듯이 by 인수로 Team을 주게 되면, pjt 데이터 프레임에서 Team이 A인 행은 하나지만, class12.a에서 Team이 A이고 학번이 15번과 18번인 학생과 관련된 두 행이 존재하므로, pjt의 한 행이 이 두 행에 차례로 결합되어 새로운 행을 만들었음을 알 수 있다. 이처럼 inner_joint()는 by 인수로 주어진 행에 동일한 값이 여러번 있으면 해당 값으로 결합이 여러번 발생한다.
두 열 이상을 기준으로 join
Join의 기준이 되는 열은 하나가 아니라 여러 개가 될 수 있다. 다음과 같은 두 개의 데이터 프레임이 있다고 하자. 그리고 이 두 데이터 프레임을 하나의 데이터 프레임으로 결합한다고 하자.
first.name last.name age
1 James Bolton 34
2 James Tiger 26
3 Goerge Tiger 47 first.name last.name income
1 Goerge Tiger 35
2 James Bolton 24
3 James Tiger 18두 데이터 프레임 각각에는 한 사람에 대한 정보는 오직 한 행에만 정보가 기술되어 있다. 그러나 두 데이터 프레임에서 first.name이 동일한 사람이 2명, last.name이 동일한 사람이 2명이 있다. 그래서 first.name이나 last.name만으로 데이터를 결합한다면 동일한 이름을 가진 사람이 있어서 원하는 결과를 얻을 수 없다. 다음은 first.name으로 결합한 결과이다.
Warning in inner_join(cAge, cIncome, by = "first.name"): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 2 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning. first.name last.name.x age last.name.y income
1 James Bolton 34 Bolton 24
2 James Bolton 34 Tiger 18
3 James Tiger 26 Bolton 24
4 James Tiger 26 Tiger 18
5 Goerge Tiger 47 Tiger 35결과에서 보듯이 cAge의 James Bolton 행은 cIncome의 James Bolton과 James Tiger 행과 first.name이 동일하므로 두 번 결합이 이루어진다. 마찬가지로 cAge의 James Tiger 행도 cIncome의 James Bolton과 James Tiger 행과 first.name이 동일하므로 역시 두 번 행 결합이 발생한다. 그래서 결합된 결과가 3건이 아니라 총 5건의 데이터 행을 갖는다.
그리고 cAge와 cIncome 모두 last.name 열이 있어서 어떤 last.name을 남겨두어야 할지 모르므로, 첫번째 데이터 프레임에서 온 열은 .x, 두번째 데이터 프레임에서 온 열은 .y라는 접미사를 붙여서 열을 만들었다.
이러한 경우는 first.name과 last.name이 모두 같은 경우에만 행이 결합되도록 하는 것이 더 바람직하다. 그렇게 하려면 이 두 열의 이름을 모두 by 인수로 전달하면 된다.
first.name last.name age income
1 James Bolton 34 24
2 James Tiger 26 18
3 Goerge Tiger 47 359.2.2 Filtering join
지금까지는 두 데이터 프레임의 키 값이 같은 행을 inner 또는 outer join으로 연결하는 방법을 살펴보았다. 그런데 어떤 경우에는 한 데이터 프레임의 데이터를 다른 데이터 프레임의 정보를 사용하여 필터링해야 하는 경우가 있다. 다음의 두 예를 고려해 보자.
어떤 도시의 거주자의 자산 데이터와 그 도시의 세금 체납자 데이터가 있다고 하자. 이 때 거주자의 자산 정보에서 세금 체납자의 자산 정보만 뽑아서 분석하려고 한다. 어떻게 이 정보를 뽑아낼 수 있을까?
어떤 텍스트에서 사용된 단어 데이터와 의마가 없는 단어인 불용어 데이터가 있다고 하자. 이 때 텍스트의 단어 데이터에서 불용어는 제외하고 데이터를 분석하려고 한다. 어떻게 이 정보를 뽑아낼 수 있을까?
dplyr 패키지에는 이 작업을 위해 다음 두 함수를 제공한다.
semi_join(x, y):x데이터 프레임에서y에 있는 데이터만 뽑아낸다. Inner join과 다른 점은 두 데이터 프레임의 정보를 결합하지 않는다는 것이다.x데이터 프레임에서 남겨둘 행을 지정하기 위해서만y를 사용한다.anti_join(x, y):x데이터 프레임에서y에 있는 행은 제외한다.
id name
1 2 b
2 3 c id name
1 1 a9.2.3 Join을 수행하는 다른 방법들
9.2.3.1 merge() 함수
R의 기본 함수인 merge() 함수는 dplyr 패키지의 inner와 outer join을 수행해 준다.
id name addr
1 2 b B
2 3 c C id name addr
1 1 a <NA>
2 2 b B
3 3 c C id name addr
1 2 b B
2 3 c C
3 4 <NA> D id name addr
1 1 a <NA>
2 2 b B
3 3 c C
4 4 <NA> Dsqldf 패키지
지금까지 dplyr의 join 함수를 이용하여 관계형 데이터베이스의 join과 유사한 데이터 결합을 어떻게 수행하는지 살펴보았다. 그런데 관계형 데이터베이스의 SQL에 익숙한 사람들은 R에서 SQL처럼 좀 더 다양한 방식으로 join을 수행할 수 없을까라는 의문을 가질 수 있다. sqldf 패키지는 SQL 문법을 이용하여 R의 데이터 프레임에서 데이터를 조회하거나 결합할 수 있도록 해 준다. 이러한 기능이 필요한 사람은 이 패키지의 문서를 참조하기 바란다. 그러나 R은 데이터 분석을 위한 도구이지 관계형 데이터베이스와 같은 일을 수행하기 위한 도구가 아님을 명심할 필요가 있다. 대량의 데이터의 결합이 필요하다면 관계형 데이터베이스에서 SQL을 이용하여 이를 먼저 수행한 후 최종 결과를 R로 보내어 분석을 수행하는 것이 일반적으로 더 효율적인 방법이다.
9.3 tidyr 패키지를 이용하여 정돈 데이터 형식으로 바꾸기
tidyr 패키지는 tidyverse 패키지에 포함된 패키지로 비정돈 형식의 데이터를 정돈 형식으로 바꾸어주는 함수를 가지고 있다.
9.3.1 pivot_longer: 여러 열에 걸친 한 변수의 데이터를 하나의 열로 길게 모으기
정돈 데이터는 한 열이 하나의 변수에 대응을 해야 한다. 그러나 현실의 데이터에서는 동일한 변수의 값이 여러 열에 흩뿌려져 있는 경우가 발생한다. 시계열 데이터들이 대표적인 사례라 할 수 있다. 다음은 tidyr에 포함된 table4a 데이터이다. 세 나라의 1999년도와 2000년도의 어떤 사건의 발생 건수를 보여주고 있다. 발생 건수를 나타내는 데이터 열이 두 개의 열로 나눠져 있음을 볼 수 있다.
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766ggplot2로 사건의 전체 건수에 대해 막대 그래프를 그리려고 해도 두 열로 나뉘어져 있어서 전체 건수에 대한 막대 그래프를 바로 그리기 어렵다. 물론 두 열을 합산한 열을 만들어 그릴 수도 있지만, 1999년도와 2000년도의 건수를 다른 색의 막대로 표현하기 어렵다.
table4a를 정돈 데이터로 바꾸려면 두 열을 한 열로 모아야 한다. tidyr의 pivot_longer() 함수는 그러한 역할을 수행한다.
# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766pivot_longer()에 모아야 할 열의 이름을 지정한다. 이 예에서는 1999와 2000이다. 두 열의 이름은 숫자로 시작하고 있어서 표준적인 형태를 따르지 않아서` `으로 둘러쌓여 표현되었다.- 원 데이터의 열 이름을 표현할 변수를
names_to로 지정한다. - 원 데이터의 열의 값을 표현할 변수를
values_to로 지정한다.
원 데이터의 열 이름은 변수로서 따옴표 없이 지정되고, 결과 데이터에 만들 열 이름은 아직 만들어진 변수가 아니므로 변수의 이름이 따옴표로 둘러쌓여 문자열로 전달된다.
이렇게 정돈된 데이터 형식으로 변형되면 데이터를 다양한 관점에서 분석할 수 있다.
table4a %>%
pivot_longer(c(`1999`, `2000`), names_to = "year", values_to ="cases") %>%
ggplot(aes(country, cases, fill=year)) + geom_col()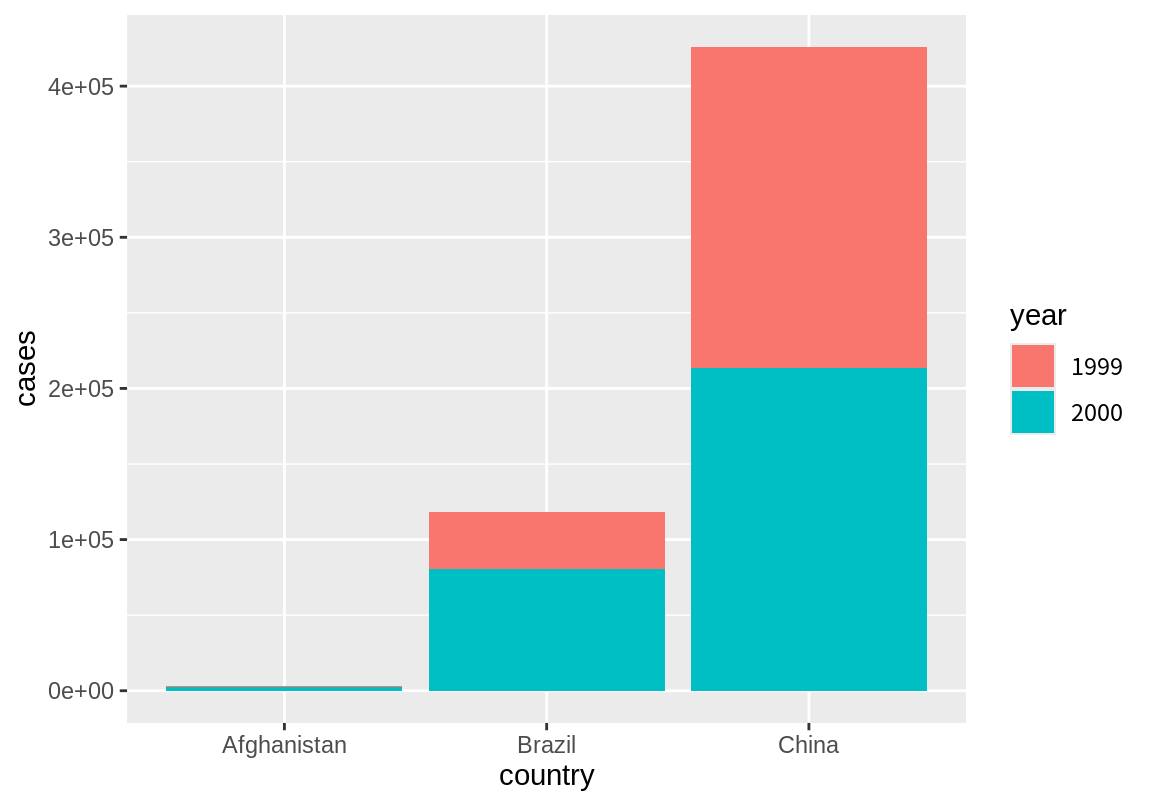
table4a %>%
pivot_longer(c(`1999`, `2000`), names_to = "year", values_to ="cases") %>%
ggplot(aes(year, cases, fill=country)) + geom_col()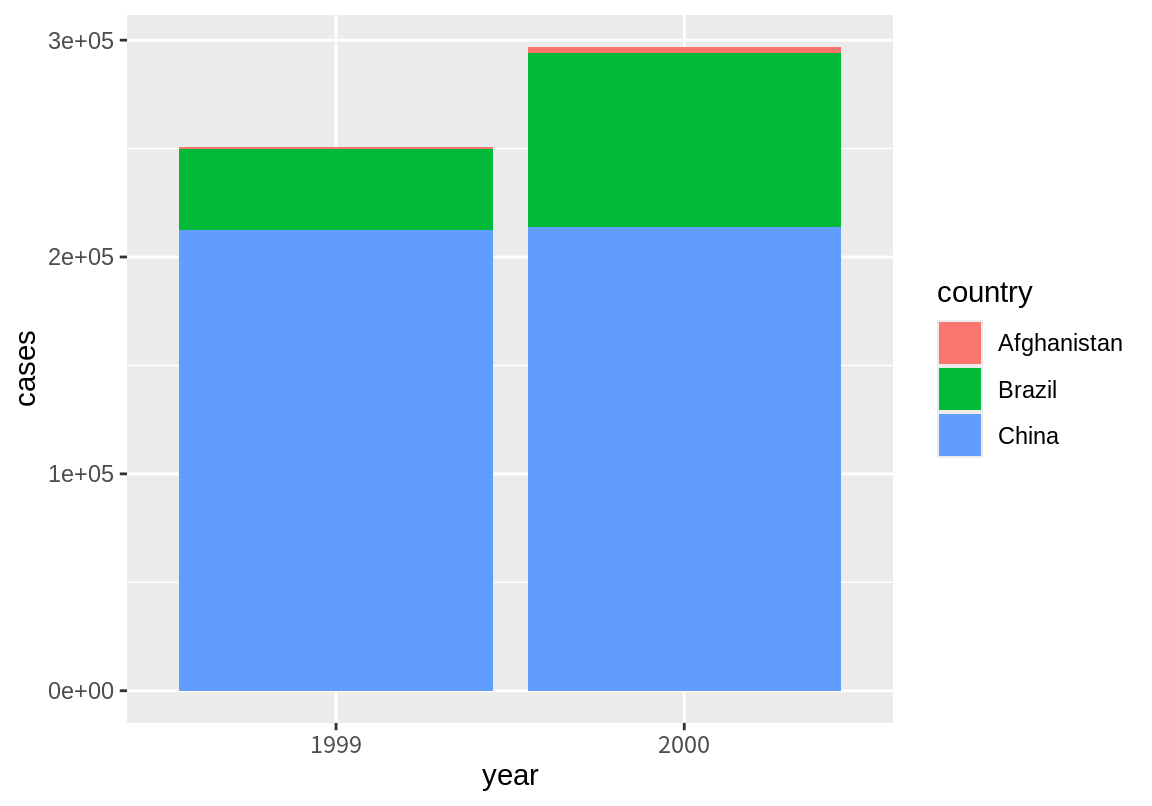
다음 그림은 앞의 pivot_longer() 함수의 작동 방식을 보여준다. 원 데이터보다 길어진 형식으로 데이터가 변환되므로 longer라는 표현이 사용되었다.

Figure 9.1: pivot_longer 작동 방식 (출처: R for Data Science)
마지막으로 pivot_longer()를 할 때 여러 열을 지정해야 하면, 이를 일일이 나열하는 것은 귀찮을 뿐만 아니라 오류 발생이 크다. 열의 나열은 select() 함수에서와 같이 :로 열의 범위를 설정하거나 열을 매칭하는 함수 등을 사용할 수 있다.
# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766결측치가 있는 경우
table4a에서 중국의 2000년도 데이터가 조사되지 않아서 NA로 표시되어 있다면 pivot_longer()는 어떤 결과를 줄까? 다음 결과에서 보듯이 결측치가 있는 셀도 모두 별도의 행으로 표현이 된다.
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 NA# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 NA만약 긴 형식에서는 결측치인 행을 없애고 싶으면 values_drop_na 인수를 TRUE로 설정한다.
na_long_table4a <- na_table4a %>%
pivot_longer(c(`1999`, `2000`), names_to = "year",
values_to = "cases", values_drop_na = T)
na_long_table4a# A tibble: 5 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258gather 함수
tidyr 패키지는 1.0 버전이 출시되면서 많은 변화가 있었다. 이전 버전의 에서는 gather() 함수가 pivot_longer() 함수의 역할을 수행하였다. 그리고 호환성을 위해 현재의 버전에서도 gather() 함수를 사용할 수 있다. 아직도 많은 R 관련 책에서 이 함수를 사용하고 있어서 사용법을 여기에 기술한다.
# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Brazil 1999 37737
3 China 1999 212258
4 Afghanistan 2000 2666
5 Brazil 2000 80488
6 China 2000 213766pivot_longer와 유사한 형식인데,gather에서는 합칠 열의 이름을 각각의 인수로 전달된다.names_to와values_to라는 원 데이터 입장에서의 인수 이름이gather에서는 합쳐진 데이터 입장에서의 인수 이름인key와value라고 기술된다.
9.3.2 pivot_wider: 한 열에 기술된 여러 변수의 데이터를 여러 열로 넓게 펼치기
정돈 데이터는 하나의 열은 하나의 변수에 대응을 해야 한다. 그러나 현실의 데이터에서는 한 열에 여러 변수의 값이 표현되어 있는 경우도 있다. 다음 데이터는 세 나라의 어떤 년도의 사건의 발생 건수와 인구수가 count라는 한 열에 표현되었다. 그렇기 때문에 count 열은 인구수와 사건 횟수라는 두 변수의 값을 모두 포함한 열이 되었다.
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583그렇기 때문에 인구수와 사건 횟수를 각각 합이나 평균을 구하거나, 인구 당 사건 횟수를 구하기 위하여 사건 회수를 인구 수로 나누는 작업도 하기가 불편하다.
table2를 정돈 데이터로 바꾸려면 count 열의 데이터를 인구수와 사건 횟수를 나타내는 열로 분리하여 한다. tidyr의 pivot_wider() 함수는 그러한 역할을 수행한다.
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583pivot_wider()는 결과 펼쳐진 결과 데이터에서 열의 이름으로 사용될 변수를names_from인수로 지정한다.- 펼쳐진 결과 데이터에서 열의 값으로 사용될 변수를
values_from인수로 지정한다.
names_from과 values_from 인수를 지정할 때, 원 데이터의 열을 지정하는 것이므로 따옴표 없이 변수로서 지정한다.
정돈 데이터 형식으로 변형되면 다음처럼 열별로 합과 평균을 구하기가 좋고 새로운 변수를 추가하기도 용이하다.
table2 %>%
pivot_wider(names_from = type, values_from = count) %>%
group_by(country) %>%
summarise(totol_case=sum(cases), mean_pop=mean(population))# A tibble: 3 × 3
country totol_case mean_pop
<chr> <dbl> <dbl>
1 Afghanistan 3411 20291216.
2 Brazil 118225 173255630
3 China 426024 1276671928.table2 %>%
pivot_wider(names_from = type, values_from = count) %>%
mutate(cases_per_capita = cases / population)# A tibble: 6 × 5
country year cases population cases_per_capita
<chr> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071 0.0000373
2 Afghanistan 2000 2666 20595360 0.000129
3 Brazil 1999 37737 172006362 0.000219
4 Brazil 2000 80488 174504898 0.000461
5 China 1999 212258 1272915272 0.000167
6 China 2000 213766 1280428583 0.000167 다음 그림은 앞의 pivot_wider() 함수의 작동 방식을 보여준다.
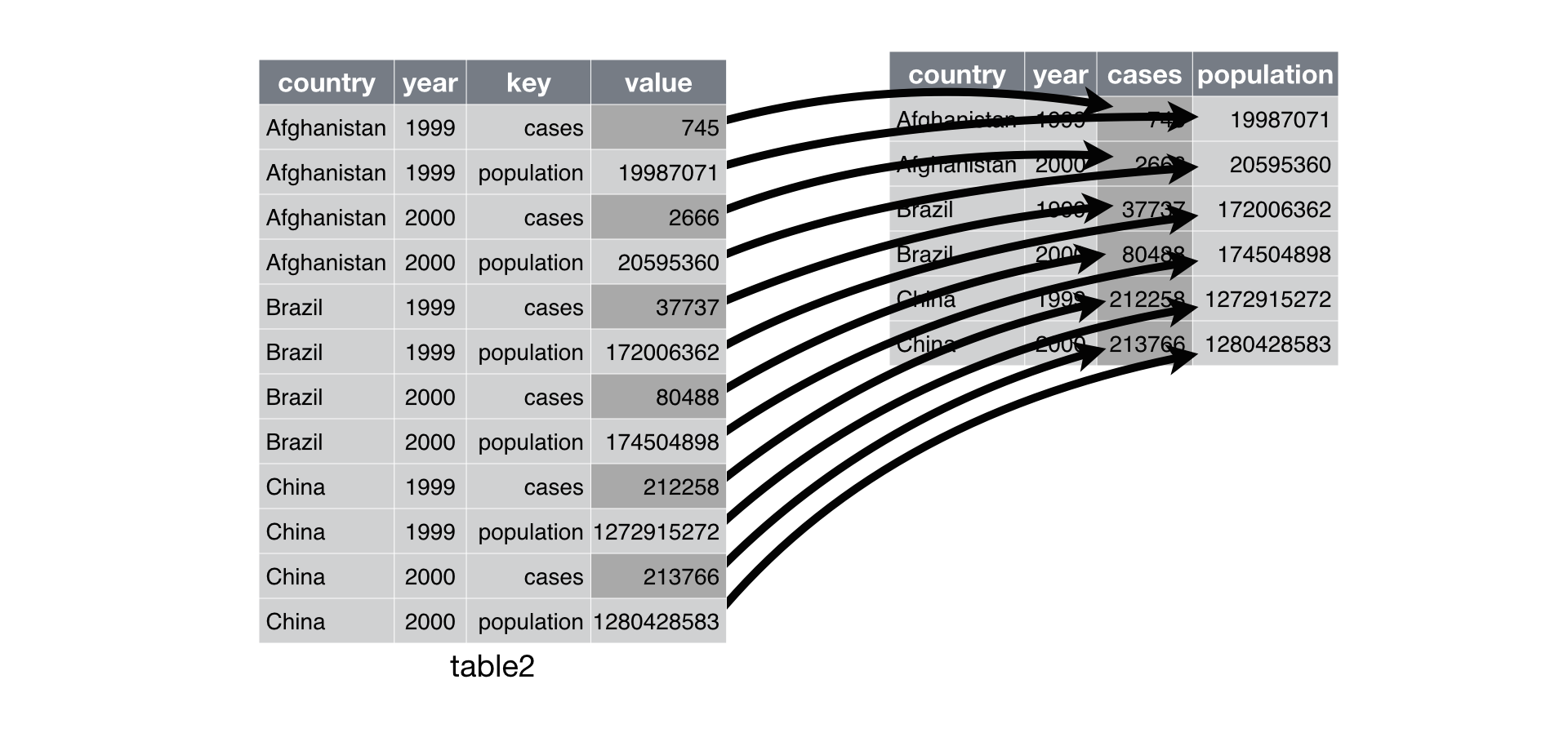
Figure 9.2: pivot_wider의 작동 방식 (출처: R for Data Science)
결측치가 있는 경우
앞서 pivot_longer()에서 중국의 2000년도 데이터에 결측값이 있는 행을 제거하여 데이터 프레임을 만들었다.
# A tibble: 5 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258만약 이 데이터를 넓은 형식으로 합치면 어떤 결과가 나올까? 결과에서 보듯이 결측이 있는 곳이 NA로 표시되고 데이터가 넓은 형식으로 변환된다.
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 NA결측치를 특정 값으로 대체할 수 있다. 앞의 데이터에서 China의 2000년 데이터가 없는 이유가 한 건도 사건이 발생하지 않은 것이라고 하면 0이라고 대체되는 것이 좋을 것이다.
values_fill 인수를 사용하면 넓은 형식으로 데이터를 변형함에 따라 만들어지는 결측치를 특정 값으로 대체할 수 있다.
# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 0values_fill 인수에 요소에 이름이 부여된 리스트를 사용하면 새롭게 만들어지는 열별로 결측치가 다르게 대체할 수도 있다.
spread 함수
tidyr 패키지는 1.0 버전이 출시되면서 많은 변화가 있었다. 이전 버전의 에서는 spread() 함수가 pivot_wider() 함수의 역할을 수행하였다. 그리고 호환성을 위해 현재의 버전에서도 spread() 함수를 사용할 수 있다. 아직도 많은 R 관련 책에서 이 함수를 사용하고 있어서 사용법을 여기에 기술한다.
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583pivot_wider와 유사한 형식인데names_from와values_from이라는 인수 이름이spread에서는key와value라고 기술된다.
9.3.3 seperate: 한 셀을 여러 셀로 분리하기
한 셀에 여러 값이 기술되어 있으면 정돈 형식의 데이터가 아니다. table3의 rate 열은 사건의 수와 인구수 데이터가 문자열 형식으로 표현된 열이다.
# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/12804285839.3.3.1 특정 문자를 기준으로 분리하기
seperate()는 정해진 열을 sep에 지정된 문자를 기준으로 분리하여 분리된 값을 into에 지정된 열 이름으로 분리한다. 앞의 다른 함수와 마찬가지로 원 데이터의 열은 변수로서 따옴표 없이 지정되었고 결과 데이터에 사용될 열 이름은 따옴표를 사용하여 문자열로 전달되었다.
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583다음 그림은 앞의 seperate() 함수의 작동 방식을 보여준다.

Figure 9.3: separate의 작동 방식 (출처: R for Data Science)
sep은 구분자로 사용할 일반 문자뿐 아니라 정규 표현식을 사용하여 문자를 분리할 수 있다.
9.3.3.2 분리한 열의 형변환
앞의 결과를 보면 rate 열의 데이터가 문자열이기 때문에 결과 열도 모두 문자열 형식임을 볼 수 있다. 그런데 cases와 population 열은 모두 숫자로서 의미를 가지고 있으므로 숫자로 변환되는 것이 좋다. 셀의 내용을 분리한 후 숫자나 논리값으로 변형이 가능하면 변형을 하려면 convert 인수를 TRUE로 설정한다.
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <int> <int>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583# A tibble: 1 × 2
total_cases mean_pop
<int> <dbl>
1 547660 490072924.9.3.3.3 문자 수를 기준으로 분리하기
sep 인수에 문자 대신 숫자를 입력하면 문자 수를를 기준으로 열을 분리한다. 양수이면 왼쪽에서 시작하여 sep에 입력된 문자 수까지와 그 이후로 열을 분리하고, 음수이면 오른쪽을 기준으로 sep에 입력된 문자 수까지와 그 이전으로 열을 분리한다.
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 /19987071
2 Afghanistan 2000 266 6/20595360
3 Brazil 1999 377 37/172006362
4 Brazil 2000 804 88/174504898
5 China 1999 212 258/1272915272
6 China 2000 213 766/1280428583# A tibble: 6 × 4
country year cases population
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745/19987 071
2 Afghanistan 2000 2666/20595 360
3 Brazil 1999 37737/172006 362
4 Brazil 2000 80488/174504 898
5 China 1999 212258/1272915 272
6 China 2000 213766/1280428 583 앞의 예에서 숫자열인 year에 적용하여 세기와 나머지 년도로 분리해 내보자.
# A tibble: 6 × 4
country century year rate
<chr> <chr> <chr> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 00 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 00 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 00 213766/1280428583만약 세기와 연도를 숫자로 표현하는 것이 필요하다면 앞서 설명한 것처럼 convert 인수를 TRUE로 설정하면 된다. 이 경우 00년도가 모두 숫자 0으로 변환된 것을 볼 수 있다.
# A tibble: 6 × 4
country century year rate
<chr> <int> <int> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 0 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 0 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 0 213766/12804285839.3.4 unite: 여러 셀의 데이터를 하나의 셀로 병합하기
separate() 함수와 반대 작용을 하는 함수가 unite() 함수이다. unite() 함수는 여러 셀의 내용을 하나의 셀로 합친다. table5는 년도 데이터가 세기(century)와 나머지 년도(year)로 나뉘어져 있는 데이터이다. 세기와 무관하게 년도 별로 데이터를 분석하려고 하면 이 두 열을 합쳐서 온전한 년도 데이터를 만들어야 한다.
# A tibble: 6 × 3
country year rate
<chr> <chr> <chr>
1 Afghanistan 19_99 745/19987071
2 Afghanistan 20_00 2666/20595360
3 Brazil 19_99 37737/172006362
4 Brazil 20_00 80488/174504898
5 China 19_99 212258/1272915272
6 China 20_00 213766/1280428583unite()의 기본 설정은 _을 구분자로 사용하여 합쳐진 셀의 내용을 연결한다. 이를 조정하려면, sep 인수를 설정하면 된다. 다음처럼 하면 구분자 없이 연결을 수행한다.
# A tibble: 6 × 3
country year rate
<chr> <chr> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/12804285839.4 데이터 열의 형식 바꾸기
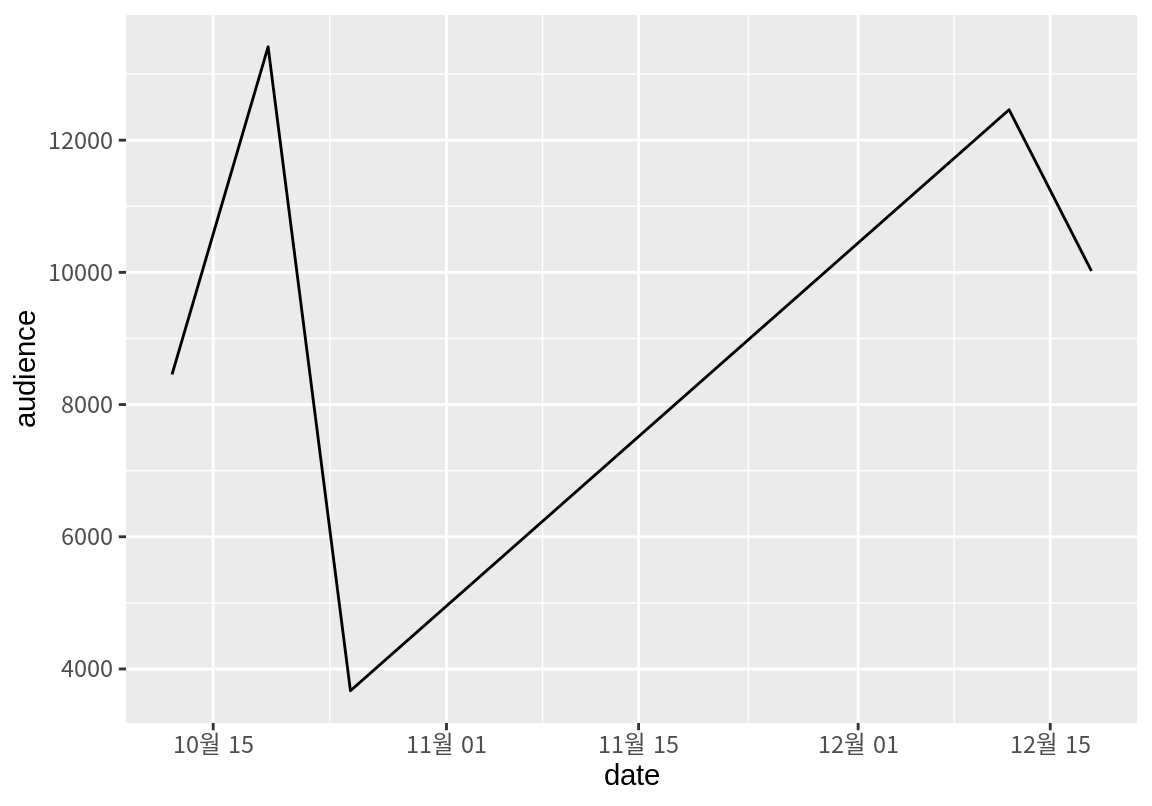
어떤 스포츠팀의 홈 경기의 관중수를 조사한 다음과 같은 데이터를 고려해 보자.
games = tribble(
~date, ~audience,
"2023/10/12", "8,456",
"2023/10/19", "13,412",
"2023/10/25", "3,671",
"2023/12/12", "12,460",
"2023/12/18", "10,021"
)
games# A tibble: 5 × 2
date audience
<chr> <chr>
1 2023/10/12 8,456
2 2023/10/19 13,412
3 2023/10/25 3,671
4 2023/12/12 12,460
5 2023/12/18 10,021 이 데이터의 문제는 날짜와 관중수가 모두 문자열로 되어 있어서 숫자 연산이 되지 않고, 날짜 간격에 따라 그래프가 적절한 간격으로 그려지지 않는다는 것이다.
Error in `summarise()`:
ℹ In argument: `total = sum(audience)`.
Caused by error in `sum()`:
! 인자의 'type' (character)이 올바르지 않습니다숫자는 천 단위로 나뉘어지는 쉼표 때문에 파일에서 데이터를 읽으면 문자로 처리되는 경우가 있다.
이를 숫자로 바꾸려면 parse_number() 함수를 사용한다.
# A tibble: 5 × 2
date audience
<chr> <dbl>
1 2023/10/12 8456
2 2023/10/19 13412
3 2023/10/25 3671
4 2023/12/12 12460
5 2023/12/18 10021# A tibble: 1 × 1
total
<dbl>
1 48020관중수는 숫자로 변환되어서 합산이 잘 수행된다. 그러나 날짜가 문자로 되어 있어서 날짜 간격을 제대로 인식하지 않아서 관중수의 선 그래프의 간격이 일정하게만 그려진다.
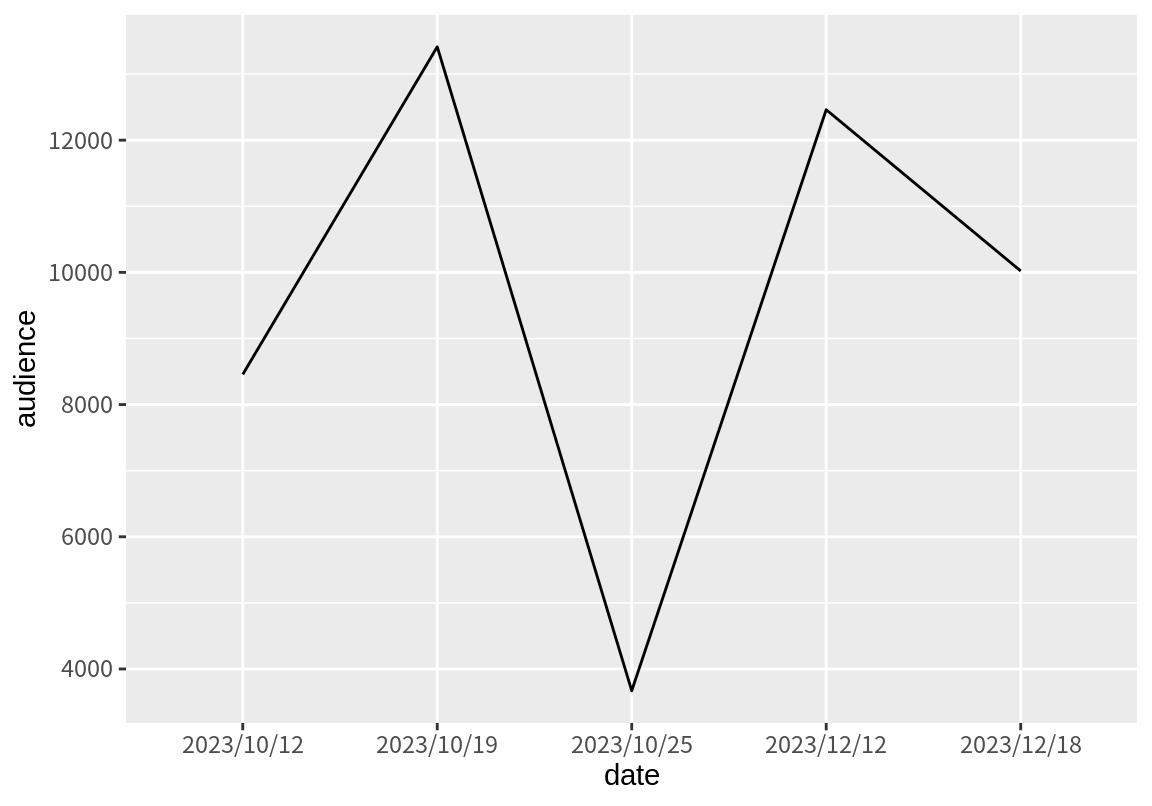
parse_datetime() 함수를 사용하면 다양한 형식으로 문자열로 표현된 날짜를 날짜 형식으로 변경할 수 있다.
format 인수에 날짜 문자열의 형식을 지정하는 방식은 parse_datetime()의 도움말을 확인하자.
[1] "2023-10-12 UTC" "2023-10-19 UTC" "2023-10-25 UTC" "2023-12-12 UTC"
[5] "2023-12-18 UTC"# A tibble: 5 × 2
date audience
<dttm> <dbl>
1 2023-10-12 00:00:00 8456
2 2023-10-19 00:00:00 13412
3 2023-10-25 00:00:00 3671
4 2023-12-12 00:00:00 12460
5 2023-12-18 00:00:00 10021