Chapter 3 R 벡터
벡터는 R의 통계 분석에서 가장 중요한 데이터 형식이다. 다른 범용의 프로그래밍 언어와는 다르게 R은 벡터 단위의 연산 및 조작을 지원함으로써 통계 데이터 분석에 매우 편리한 이점을 제공한다.
벡터는 동일 형식 데이터의 나열
벡터는 50명 학생들의 키 데이터 (162.1, 175.8, 183.2, …), 50명 학생들의 성별 데이터 ("여", "남", "남", ...)처럼 한가지 타입의 데이터를 나열한 것이다. 여기서 타입이란 1, 2 등의 숫자 타입, "yes", "no" 등의 문자열 타입, TRUE/FALSE의 논리적 타입을 의미한다. 숫자 벡터에는 숫자 데이터만 나열되고, 문자 벡터나 논리 벡터에는 각각 문자열과 논리값만이 나열된다.
벡터의 길이/크기
벡터가 포함하고 있는 데이터의 개수를 벡터의 길이 또는 크기라고 한다. 따라서 50 명 학생의 키 데이터는 길이가 50인 벡터가 된다. 사실 R은 벡터가 아닌 숫자, 문자, 논리값은 없다. 10이라는 숫자 하나도 사실은 길이가 1인 숫자 벡터이고, 문자열도 논리값도 길이가 1인 문자 벡터와 논리 벡터일 뿐이다.
3.1 숫자 벡터
3.1.1 c() 함수를 이용한 숫자 벡터 만들기
숫자 연결하여 벡터 만들기
c() 함수는 여러 가지 기능을 하지만 가장 중요한 기능은 두개 이상의 벡터를 인수로 받아 이를 연결(concatenating)하여 새로운 벡터를 만드는 것이다. 다음은 c() 함수로 숫자 2, 4, 6, 8, 10으로 이루어진 숫자 벡터를 만들어 y라는 변수에 할당하는 예이다.
[1] 2 4 6 8 10R 콘솔 상에 변수 y를 입력한 후 Enter를 치면 변수 y의 내용을 출력한다. 변수가 벡터인 경우에는 벡터의 요소들을 나열한다.
앞의 예에서는 정수만으로 이루어진 벡터를 만들었는데 이번에는 실수가 들어간 숫자 벡터를 만들어 보자. 실수 하나가 벡터의 요소로 들어가자 나머지 숫자도 소수점을 가지는 실수로 표현됨을 볼 수 있다.
[1] 1.0 3.0 5.0 7.0 9.2길이가 2 이상인 벡터 연결하여 새 벡터 만들기
지금까지는 숫자(길이가 1인 숫자 벡터)만을 연결하여 숫자 벡터를 만들었다. 이제 길이가 2 이상인 숫자 벡터 x와 y를 연결하여 새로운 숫자 벡터 z를 만들어 보도록 하자.
[1] 1.0 3.0 5.0 7.0 9.2 2.0 4.0 6.0 8.0 10.0위의 예에서 x와 y의 위치가 바뀌면 어떻게 될까? 아래 결과에서 볼 수 있듯이 새롭게 생긴 z 벡터의 요소의 순서가 바뀐다. y의 요소 다음에 x의 요소들이 차례대로 나열된다.
[1] 2.0 4.0 6.0 8.0 10.0 1.0 3.0 5.0 7.0 9.2여러 줄에 걸친 벡터 출력
c() 함수는 세 개 이상의 벡터를 연결시킬 수도 있다. 아래 결과에서 벡터 w는 x, y, z의 요소들이 차례로 나열되어 새 벡터가 되었음을 볼 수 있다. 이 때 벡터가 길어 여러 줄로 출력이 되었다. 출력 결과 중 [1]과 [11]은 첫째 줄은 벡터의 1번째 요소부터, 둘째 줄은 11번째 요소부터 출력되고 있음을 나타낸다. 이렇듯 벡터가 길어 여러 줄로 콘솔에 출력되면 각 줄의 맨 앞에 표시되는 요소가 벡터의 몇 번째 요소인지를 알려준다.
[1] 1.0 3.0 5.0 7.0 9.2 2.0 4.0 6.0 8.0 10.0
[11] 2.0 4.0 6.0 8.0 10.0 1.0 3.0 5.0 7.0 9.23.1.2 패턴을 이용한 숫자 벡터 만들기
R의 데이터를 다루다 보면 어떤 패턴을 따르는 숫자 벡터가 필요한 경우가 있다. 예를 들어 50명의 학생에게 1부터 50까지 차례로 일련번호를 부여하려고 한다고 하자. c() 함수를 이용하여 1부터 50까지 숫자를 일일이 연결하여 이를 만드는 것은 매우 번거로운 일이다. 이러한 경우에는 n:m 명령을 사용하여, 숫자 n부터 시작하여 숫자 m까지 1씩 증가하거나 감소하는 수열로 된 벡터를 쉽게 만들 수 있다.
n:m
[1] 1 2 3 4 5 6 7 8 9 10 [1] 10 9 8 7 6 5 4 3 2 1위 결과에서 보듯이 m이 n보다 크면 1씩 증가하는 수열을, n이 m보다 크면 1씩 감소하는 수열이 생성된다. 위의 예는 자연수만을 사용하였는데, 사실 수열의 시작과 끝을 나타내는 숫자는 음의 정수나 실수 등 어떠한 숫자도 가능하다. n이 정수가 아닌 경우도 n부터 시작하여 1씩 증가 또는 감소하여 m을 넘지 않는 수열을 만든다는 사실은 변함이 없다.
[1] -4 -3 -2 -1 0 1 2 3 4 5 6 7 8[1] 0.7 1.7 2.7 3.7 4.7 5.7 6.7 7.7[1] 2.3 1.3 0.3 -0.7 -1.7 -2.7 -3.7 -4.7seq()
seq() 함수를 이용하면 1씩 증가하거나 감소하는 수열 벡터뿐 아니라 좀 더 복잡한 수열 벡터도 생성할 수 있다.
seq() 함수는 입력 인수의 형태에 따라 생성하는 수열이 다르다. seq(n, m)으로 함수를 호출하면 n:m과 마찬가지로 1씩 증가하거나 감소하는 수열을 생성한다. seq(n, m, by=k)로 호출하면 n부터 시작하여 k씩 증가하여 m을 넘지 않는 수열을 생성한다. seq(length=j, from=n, by=k)로 호출하면 n부터 시작하여 k씩 증가하는 길이가 j인 수열을 만든다.
[1] 5 6 7 8 9 10 11 12 13 14 15[1] 5 7 9 11 13 15 [1] -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.51부터 어떤 벡터의 길이까지 일련번호를 생성할 때 seq() 함수를 이용하면 편리하다. seq()의 along 인수에 벡터를 부여하면 1부터 그 벡터의 길이만큼의 일련번호가 생성된다.
[1] 2 4 6 8 10[1] 1 2 3 4 5rep()
어떤 벡터를 반복시켜서 새로운 벡터를 만들고 싶을 때는 rep() 함수를 이용한다. 첫번째 인수에 반복할 벡터를, times 인수에 반복할 횟수를 부여한다. rep() 함수를 빈번하게 이용하는 경우가 숫자 하나를 여러번 반복하여 벡터를 만들 때이다.
[1] 1 2 3 4 5 0 -1 -2 -3 -4 -5 1 2 3 4 5 0 -1 -2 -3 -4 -5 [1] 1 1 1 1 1 1 1 1 1 1rep() 함수를 이용하면 벡터 전체를 차례로 반복시키는 것뿐 아니라, 요소별로 횟수만큼 반복시킨 후 이를 결합하여 새로운 벡터를 만들 수도 있다. 이 경우에는 times 인수 대신 each 인수에 반복할 회수를 부여한다.
[1] 1 1 2 2 3 3 4 4 5 5 0 0 -1 -1 -2 -2 -3 -3 -4 -4 -5 -53.1.3 숫자 벡터의 연산
요소 단위 연산 (elementwise operation)
R의 강점 중 하나가 벡터의 요소끼리 연산을 지원한다는 것이다. 이는 여타의 범용 프로그래밍 언어에서는 볼 수 없는 점이다. 길이가 동일한 두 벡터에 더하기나 곱하기 연산 등을 수행하면, 같은 위치에 있는 요소끼리 해당 연산이 이루어진다(그림 3.1 참조).
[1] 0 10 20 30 40[1] 1 2 3 4 5[1] 1 12 23 34 45[1] -1 8 17 26 35[1] 0 20 60 120 200[1] 0.000000 5.000000 6.666667 7.500000 8.000000다른 범용 프로그래밍 언어에 대한 지식이 있는 독자라면, 이를 해당 언어로 구현하려면 어떻게 해야 할지 잠시 생각해 보자. 반복문을 이용하여 이를 수행해야 할 것이다. 이러한 점을 고려하면 R이 벡터 연산을 얼마나 편리하게 수행하게 해 주는지 이해할 수 있을 것이다.
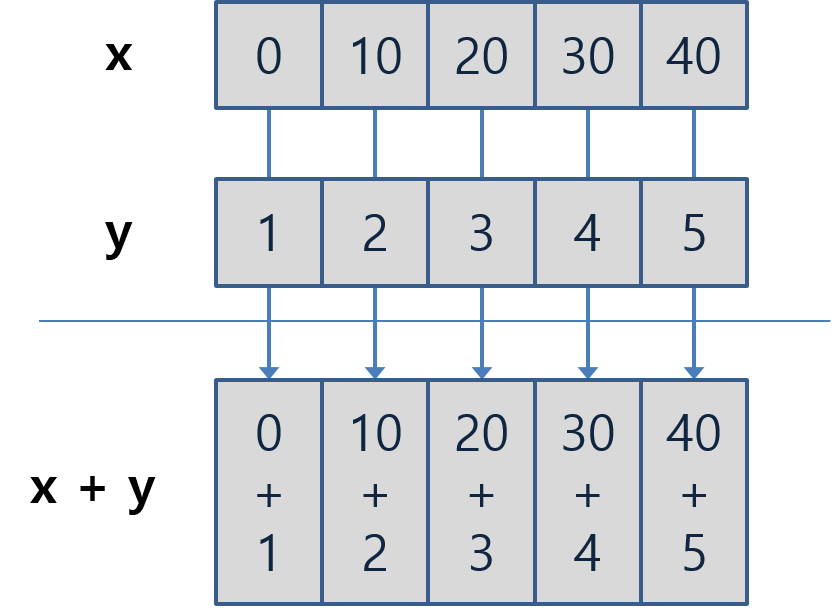
Figure 3.1: 길이가 같은 벡터의 연산
벡터 재사용 (recycling)
연산에 사용되는 두 벡터의 길이가 다르면 어떻게 될까? 이 경우 길이가 짧은 벡터의 요소들이 순환 반복되어 사용된다(그림 3.2 참조). 이러한 현상을 벡터의 재사용(recycling)이라고 부른다.
다음 예는 길이가 10인 z 벡터와 길이가 5인 y 벡터를 더한 결과를 보여준다. 결과에서 보듯이 z의 10개 요소와의 더하기 위해, y의 요소가 차례대로 한번 사용된 후 다시 한번 더 반복되어 사용되었다. (더한 결과의 일의 자리를 살펴보면 이를 확인할 수 있다).
[1] 0 10 20 30 40 0 10 20 30 40 [1] 1 12 23 34 45 1 12 23 34 45다음은 길이가 11인 w 벡터와 길이가 5인 y 벡터를 더한 예이다. 이 경우에도 w의 11개 요소와 대응되기 위해서 y의 전 요소가 두 번 반복되어 이용되고 마지막으로 y의 첫째 요소가 다시 재사용되었음을 볼 수 있다(그림 3.2 참조). 이처럼 두 벡터의 길이가 서로 배수가 아닌 경우에는 혹시 사용자의 착각일 수도 있기 때문에 경고 메시지가 출력된다. 경고 메시지는 오류가 아니므로 계산 수행은 정상적으로 수행된다.
[1] 0 10 20 30 40 0 10 20 30 40 50Warning in w + y: 두 객체의 길이가 서로 배수관계에 있지 않습니다 [1] 1 12 23 34 45 1 12 23 34 45 51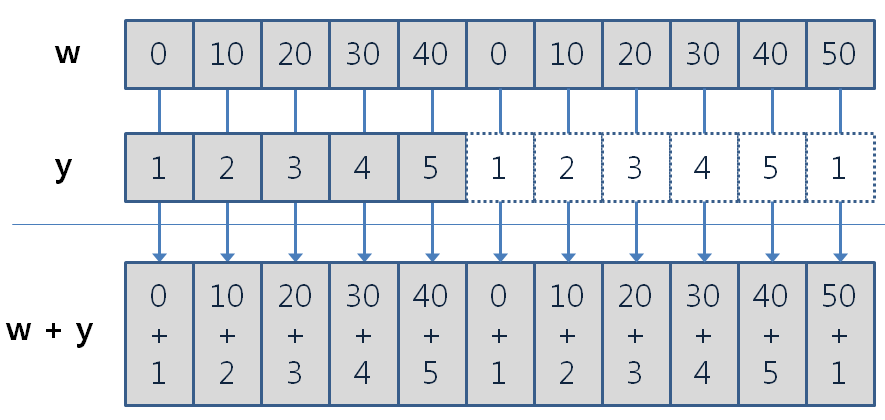
Figure 3.2: 길이가 다른 벡터의 연산
사실 길이가 다른 벡터 간의 연산이 가장 빈번히 사용되는 경우는 숫자 하나와 숫자 벡터간의 연산이다. 이 경우 숫자 하나가 벡터의 길이만큼 재사용되어 연산이 이루어진다.
[1] 10 20 30 40 50[1] 11 12 13 14 15[1] 10.000000 5.000000 3.333333 2.500000 2.000000[1] 1 4 9 16 25| 함수명 | 함수 설명 |
|---|---|
| length(x) | 벡터 x의 길이를 반환한다. |
| sum(x) | 벡터 x에 있는 모든 요소들을 더한 결과를 반환한다. |
| mean(x) | 벡터 x에 있는 요소들의 평균을 반환한다. |
| var(x) | 벡터 x에 있는 요소들의 분산을 반환한다. |
| sd(x) | 벡터 x에 있는 요소들의 표준편차를 반환한다. |
| range(x) | 벡터 x에 있는 요소들의 최소값과 최대값을 반환한다. |
| min(x)/max(x) | 벡터 x에 있는 요소들의 최소값/최대값을 반환한다. |
| median(x) | 벡터 x에 있는 요소들의 중위수를 반환한다. |
| rank(x) | 벡터 x의 각 요소를 작은 것에서 큰 것까지 순위를 반환한다. |
| sort(x) | 벡터 x의 각 요소를 순서대로 배열한다. |
| order(x) | 벡터 x의 요소의 값이 가장 작은 것부터 |
| 가장 큰 것까지 순서대로 요소의 위치를 반환한다. | |
| which.max(x) | 벡터 x의 최대값/최소값의 위치를 반환한다. |
| which.min(x) | |
| which(x) | 벡터 x에서 조건을 만족하는 요소의 위치를 반환한다. |
숫자 벡터를 인수로 하는 함수
숫자 벡터에 사칙연산 등의 수학 연산뿐 아니라, R에서 제공하는 다양한 함수도 적용할 수 있다. 숫자 벡터를 인수로 하는 함수들은 많이 있는데, 그 중 대표적인 함수들을 표 3.1에 제시하였다. 다음은 숫자 벡터에 함수를 적용한 예이다.
[1] 11 3 4 20 5[1] 5[1] 43[1] 8.6[1] 50.3[1] 7.092249[1] 50.3[1] 3 20[1] 3[1] 20[1] 5[1] 4[1] 2[1] 1 4[1] 1벡터의 순서 및 정렬 관련 함수
R은 벡터 요소들의 크기 순서, 정렬을 해주는 rank(), order(), sort() 함수가 있다. rank() 함수는 벡터 요소의 크기 등수를 작은 것에서 큰 것 순으로 1에서부터 등수를 매겨준다. 즉, rank() 함수 결과의 첫번째 요소는 원래 벡터의 첫번째 요소의 크기 등수이다.
반면 order() 함수는 작은 것부터 큰 것 순으로 요소의 원래 벡터에서의 위치를 알려준다. 즉, order() 함수 결과의 첫번재 요소는 원래 벡터에서 가장 작은 요소가 어느 위치에 있는지를 알려준다.
그림 3.3는 앞의 설명을 도식화하여 보여준다.
[1] 4 1 2 5 3[1] 3 4 5 11 20[1] 2 3 5 1 4Figure 3.3: rank() 함수와 order() 함수의 비교
3.2 논리 벡터
R은 숫자뿐 아니라 논리값으로 구성된 벡터를 만들 수 있다. 논리 벡터의 요소들은 TRUE, FALSE, NA (not available) 값을 가질 수 있다.
c()로 논리 벡터 만들기
논리 벡터도 숫자 벡터와 마찬가지로 논리값을 c() 함수로 연결하여 만들 수 있다. 아래 예에서 보듯이 TRUE와 FALSE 대신 혼동의 여지가 없는 경우에는 T와 F 만 입력하여도 TRUE와 FALSE로 인식함을 볼 수 있다.
[1] TRUE FALSE TRUE비교 연산으로 논리 벡터 만들기
논리 벡터는 위의 예처럼 c() 함수로도 만들 수 있지만 많은 경우 벡터의 비교 연산의 결과로서 만들어진다. 다음은 비교 연산을 통해 논리 벡터를 생성한 예이다. ‘<’, ‘<=’, ‘>’, ‘>=’, ‘==’, ‘!=’ 등의 비교 연산이 벡터 요소별로 수행되어 논리 벡터가 생성되었다.
[1] FALSE FALSE FALSE TRUE TRUE[1] FALSE FALSE TRUE TRUE TRUE[1] TRUE TRUE TRUE TRUE FALSE[1] TRUE TRUE TRUE TRUE TRUE[1] FALSE TRUE FALSE FALSE FALSE[1] TRUE FALSE TRUE TRUE TRUE논리 연산으로 논리 벡터 만들기
기존 논리 벡터들에 대해 논리 연산을 수행하여 새로운 논리 벡터를 만들 수도 있다. 다음은 ‘&’, ‘’, ‘!’ 등의 논리 연산자를 이용하여 논리 벡터에 대해 AND, OR, NOT 연산을 수행한 예이다.
[1] FALSE TRUE FALSE[1] FALSE FALSE FALSE[1] TRUE TRUE TRUE논리 벡터 함수: any()와 all()
논리 연산은 아니지만 논리 벡터에 자주 사용되는 함수가 any()와 all() 함수이다. 이 함수를 이용하면 논리 벡터의 논리값 중 하나라도 TRUE가 있는지 또는 모든 논리값이 TRUE인지를 확인할 수 있다.
[1] FALSE[1] TRUE[1] FALSE[1] TRUEany()와 all()을 비교 연산자와 함께 이용하면 어떤 조건을 만족하는 요소가 벡터에 하나라도 있는지 또는 모든 요소가 조건을 만족하는지를 쉽게 확인할 수 있다.
[1] 2 10 4 22 16 10 18 26 34 17 28 14 20 24 28 26 34 34 46
[20] 26 36 60 80 20 26 54 32 40 32 40 50 42 56 76 84 36 46 68
[39] 32 48 52 56 64 66 54 70 92 93 120 85[1] TRUE[1] FALSE[1] FALSE[1] TRUE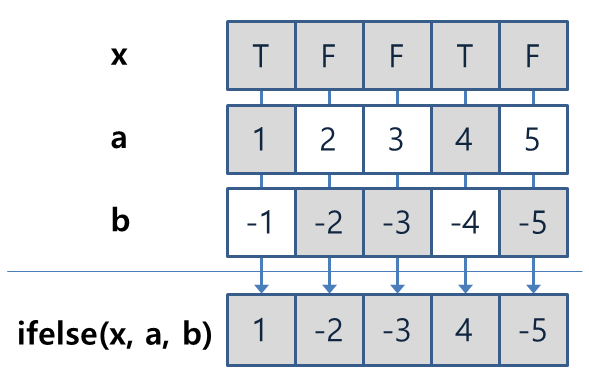
Figure 3.4: ifelse() 함수 연산
논리 벡터 함수: ifelse()
ifelse() 함수는 논리 벡터를 이용하는 또 다른 벡터 연산 함수이다. ifelse(x, a, b)로 호출되는데, x에는 논리 벡터, a와 b에는 (원칙적으로는) x의 길이와 동일한 벡터가 부여된다. ifelse() 함수는 x의 요소가 TRUE인 경우에는 벡터 a의 요소를, FALSE인 경우에는 벡터 b의 요소를 선택하여 x와 길이가 동일한 새로운 벡터를 만들어 낸다. 그림 3.4은 다음 예처럼 a 벡터가 1:5, b 벡터가 -1:-5일 때, x 벡터의 논리값에 따라 a와 b의 요소 중 어떤 요소가 선택되어 새로운 벡터가 만들어지는지를 보여준다.
[1] 1 -2 -3 4 -5ifelse()의 첫번째 인수로 논리 벡터가 직접 부여되기보다는 비교 연산의 결과가 부여되는 경우가 많다. 다음은 벡터 y에서 양수인 요소는 그대로 두고, 0이하인 요소는 0이 되도록 하여 새로운 벡터를 만든 예이다.
[1] 1 0 0 4 0위의 결과가 나온 이유는 다음과 같다. 첫번째 x 인수에 y와 0을 비교하는 연산이 들어갔다. 이 비교 연산은 다음과 같이 y보다 큰 요소에만 TRUE를 주는 논리값 벡터를 반환한다.
[1] TRUE FALSE FALSE TRUE FALSE두번째 a 인수에는 y가 부여되었으므로로 위의 비교 연산에서 TRUE가 된 위치에는 y 요소가 선택된다. 그리고 세번째 b 인수에는 0이 들어갔다. x 위치에 들어간 벡터의 요소가 5개인데, b 위치에 들어간 벡터는 요소가 1개이므로 숫자 벡터의 연산에서와 마찬가지로 0이 5번 재사용된다. 그러므로 x의 값이 FALSE인 위치에 0이 들어가게 된다 (그림 3.5 참조).
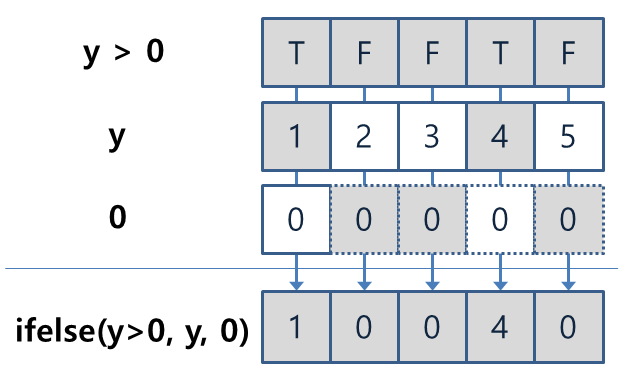
Figure 3.5: ifelse() 함수 연산에서의 벡터 재사용
3.3 문자 벡터
문자 벡터는 문자를 요소로 하는 벡터이다. 범주형 데이터를 다루거나 데이터에 이름을 부여할 때 자주 이용된다.
문자 벡터 만들기
문자 벡터의 생성은 숫자나 논리 벡터처럼 c() 함수를 이용하여 생성할 수 있다.
[1] "길동" "철수" "Tom" 숫자나 논리 벡터를 as.character() 함수를 이용하여 문자 벡터로 변환할 수도 있다. 다음 예에서 n은 숫자 벡터로 따옴표 없이 값이 표시되고, num은 문자 벡터로 모든 요소가 따옴표로 둘러싸여 표시됨을 확인한다.
[1] 1 2 3[1] "1" "2" "3"paste()로 문자 벡터 연결하기
문자 벡터에 많이 사용되는 연산 중 하나가 문자 벡터를 요소끼리 서로 연결시키는 연산이다. paste() 함수로 이러한 문자 벡터 연결을 수행할 수 있는데, 호출 시 sep 인수를 사용하지 않으면 연결되는 벡터의 요소는 공백으로 연결되고, sep 인수가 사용되면 sep 인수에 부여된 문자열이 연결되는 요소 사이에 구분자로 들어간다.
[1] "길동 1" "철수 2" "Tom 3" [1] "길동1" "철수2" "Tom3" [1] "길동-1" "철수-2" "Tom-3" [1] "길동 1" "철수 2" "Tom 1" 마지막 예에서 문자 벡터의 길이가 다르면 숫자 벡터의 연산처럼 길이가 짧은 벡터의 요소가 재사용됨을 볼 수 있다. 또 paste() 적용시 숫자 벡터가 자동으로 문자 벡터로 변환되어 연결되었음을 볼 수 있다.
paste() 함수는 세 개 이상의 문자 벡터를 연결하는 데에도 사용될 수 있다.
[1] "길동 1 A !" "철수 2 B !" "Tom 3 C !" strsplit()로 문자 벡터 분리하기
paste()와 반대의 역할을 하는 함수가 strsplit()이다. strsplit()는 paste()와는 달리 문자열을 나눌 때 구분자로 사용할 문자열을 split 인수로 반드시 제공해야 한다. 마지막 예에서 x와 split의 요소가 같은 위치끼리 적용되어 문자열 분리가 수행되었음을 확인할 수 있다.
[[1]]
[1] "2015-3-15" "10:12:12"
[[2]]
[1] "2016-10-11" "11:12:13"
[[3]]
[1] "2014-7-8" "02:03:04"[[1]]
[1] "2015" "3" "15 10:12:12"
[[2]]
[1] "2016" "10" "11 11:12:13"
[[3]]
[1] "2014" "7" "8 02:03:04"[[1]]
[1] "2015-3-15 10" "12" "12"
[[2]]
[1] "2016-10-11 11" "12" "13"
[[3]]
[1] "2014-7-8 02" "03" "04" [[1]]
[1] "2015" "3" "15 10:12:12"
[[2]]
[1] "2016-10-11 11" "12" "13"
[[3]]
[1] "2014-7-8" "02:03:04"nchar()로 문자수 세기
nchar() 함수는 문자 벡터의 각 요소의 문자 개수를 알려 준다. 공백도 문자이므로 문자 개수를 셀 때 포함이 된다는데 주의한다.
nchar("날짜")[1] 2a <- c("날짜", "day", "date", "날짜와 시간")
nchar(a)[1] 2 3 4 6| 함수명 | 함수 설명 |
|---|---|
| nchar(x) | 벡터 x의 문자열 요소의 문자 수를 반환한다. |
| substr(x, start, stop) | 벡터 x의 문자열 요소의 start번째 문자부터 stop번째 문자까지의 부분 문자열을 출력한다. |
| grep(pattern, x, ignore.case=F, fixed=F) | 벡터 x의 문자열 요소에 pattern 문자열 요소가 있는지 검색한다. pattern은 정규식일 수 있다. |
| sub(pattern, replacement, x, ignore.case=F, fixed=F) | 벡터 x의 문자열 요소에서 pattern을 찾아 replacement로 대체한다. |
| strsplit(x, split, fixed=F) | 벡터 x의 문자열 요소를 split에서 분리한 결과를 반환한다. |
| paste(…, sep=’ ’) | 문자 벡터를 sep를 이용하여 결합시킨 결과를 반환한다. |
| toupper(x) | 벡터 x의 문자열 요소를 대문자로 변환한다. |
| tolower(x) | 벡터 x의 문자열 요소를 소문자로 변환한다. |
이외에도 다양한 문자 벡터 함수가 존재한다. 그 중 대표적인 함수를 표 3.2에 제시하였다.
3.4 결측치 (Missing Values)
NA
R에서는 데이터에 결측치가 있을 때 이를 NA 값으로 표시한다. 예를 들어 5명의 학생의 키 데이터가 있는데 마지막 학생의 데이터를 얻지 못하였다면, 그 학생의 데이터는 NA로 값을 입력한다.
is.na()와 na.omit()
is.na() 함수를 이용하면 결측치의 포함 여부나 위치를 확인할 수 있다. is.na()는 벡터에서 결측치가 있는 위치는 TRUE, 결측치가 아닌 위치는 FALSE로 하는 논리 벡터를 결과로 반환한다. na.omit() 함수를 이용하면 결측치를 제외한 벡터를 만들 수 있다. na.omit()에 대한 자세한 설명은 도움말을 참조하기 바란다.
[1] 11 12 13 NA[1] FALSE FALSE FALSE TRUE[1] 11 12 13
attr(,"na.action")
[1] 4
attr(,"class")
[1] "omit"na.rm 인수
숫자 벡터에 결측치가 있으면 sum()이나 mean() 함수 등의 결과는 NA로 출력된다. 숫자 벡터에 결측치가 있기 때문에 합이나 평균을 알 수 없다는 의미이다. 만약 결측치를 제외하고 합이나 평균을 구하고 싶으면, 이들 함수를 호출할 때 na.rm=TRUE 인수를 추가하여야 한다. 그러면 결측치를 제외하고 해당 결과를 계산하게 할 수 있다.
[1] NA[1] 36NaN
결측치는 아니지만 데이터의 값을 결정할 수 없는 경우가 있다. 대표적인 경우가 0에서 0을 나누는 경우이다. 이 경우 숫자 연산의 결과를 결정할 수 없으므로 NaN(Not a Number)로 결과를 표현된다. 주의할 점은 R은 무한대도 숫자로 간주하므로, 무한대의 결과가 나올 때는 Inf로 결과를 표현한다. 다음 예에서 앞의 두 계산은 무한대로, 뒤의 두 계산은 값을 결정할 수 없어 NaN로 결과를 반환함을 볼 수 있다.
[1] Inf[1] Inf[1] NaN[1] NaNis.nan()
벡터에 NaN가 포함되어 있는지를 확인하려면 is.nan() 함수를 사용하면 된다. is.na()와 마찬가지로 NaN 요소가 있는 위치를 TRUE 값으로 하는 논리 벡터를 반환한다. 다음 예에서 보듯이 NaN가 포함되었는지를 정확히 알기 위해서는 is.na()가 아니라 is.nan() 함수를 실행하여야 한다. 왜냐하면 is.na() 함수는 NaN뿐 아니라 NA도 TRUE로 반환하기 때문이다.
[1] -Inf NaN Inf[1] FALSE TRUE FALSE[1] FALSE TRUE FALSE TRUE[1] FALSE TRUE FALSE FALSE통계 데이터에는 결측치가 자주 발생한다. 그리고 결측치 처리는 통계 분석에서 매우 중요한 문제 중 하나이다. R에서 결측치를 처리하는 다양한 기법에 대해서는 R in Action2의 18장을 참조하기 바란다.
3.5 인덱스 벡터와 필터링
데이터를 분석하다 보면, 데이터의 특정 요소만 추출하여 분석해 보고 싶을 때가 있다. 40세 이상의 고객만 추출하여 분석한다든지, 남자 학생에 대해서만 별도의 분석을 하는 경우가 그러한 예라고 할 수 있다. 이렇게 데이터에서 특정 부분만 추출하여 새로운 데이터를 만드는 작업을 필터링(filtering)이라고 한다.
벡터 필터링은 특정 벡터에서 특정 요소만을 추출하는 것을 의미한다. R에서 벡터 필터링은 인덱스 벡터를 이용하여 수행된다. 여기서 인덱스란 벡터에서 특정 요소의 위치를 의미한다. 예를 들어 5개의 요소로 구성된 벡터에서 두번째 요소를 추출하려면 두번째라는 위치가 그 요소의 인덱스가 된다. 그런데 어떤 벡터에서 추출하고자 하는 요소가 여러 개일 수도 있다. 이 경우 추출해야할 위치를 여러 개 나열해야 하고, 이렇게 나열한 요소의 위치 정보를 인덱스 벡터라고 한다. 물론 하나의 요소만 추출하고자 한다면 인덱스 벡터는 길이가 1이 될 것이다.
벡터 필터링을 하려면 다음처럼 벡터의 이름 다음에 인덱스 벡터를 대괄호 안에 기술하면 된다.
인덱스 벡터는 자연수 벡터, 음의 정수 벡터, 논리 벡터, 이름 벡터의 네 가지 형태를 가질 수 있다. 이를 각각 살펴보도록 하자.
3.5.1 자연수 인덱스 벡터
자연수 인덱스는 추출할 요소의 위치를 자연수로 표현한다. 벡터의 첫번째 요소의 위치는 1로, 두번째 요소의 위치는 2로 하여, 요소의 위치를 차례대로 1부터 벡터 길이까지의 자연수로 표현한다. 아래 예는 10개의 요소로 이루어진 벡터 x에서 자연수 인덱스 벡터로 새로운 벡터를 추출한 예이다(그림 3.6 참조). 마지막 예처럼 인덱스 벡터에서 자연수가 반복되면 해당 위치에 있는 요소가 반복되어 추출됨을 볼 수 있다.
[1] 16[1] 16 20[1] 13 15 17 19[1] 12 14 12 14 12 14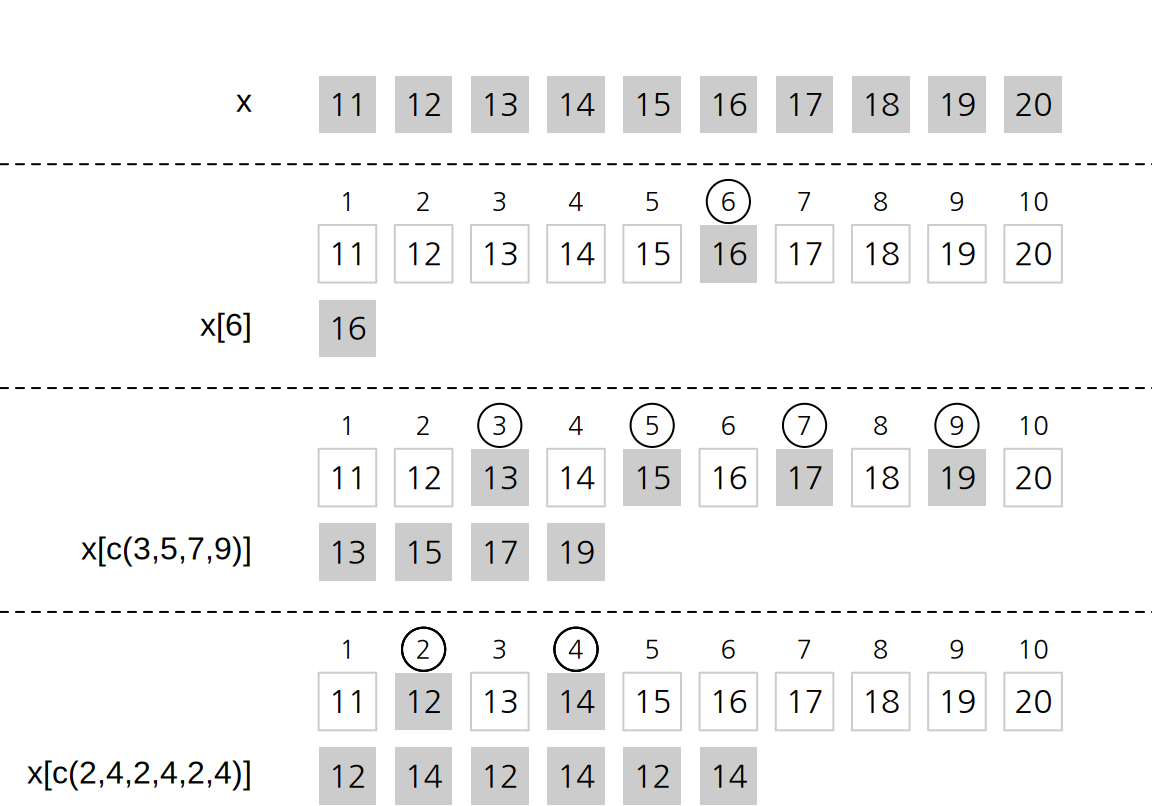
Figure 3.6: 자연수 인덱스 벡터를 이용한 벡터 필터링
인덱스 벡터를 사용하여 여러 요소를 뽑을 때 주의할 점이 있다. 벡터의 필터링에서 대괄호 안에는 오직 하나의 인덱스 벡터만 기술될 수 있다는 것이다. 만약 2개 이상의 요소를 뽑아야 한다면, c() 등으로 연결하여 하나의 인덱스 벡터로 만든 후 대괄호에 넣어야 한다. 만약 이를 실수하여 다음처럼 뽑을 요소를 각각 기술하게 되면 오류가 발생한다.
Error in x[6, 10]: incorrect number of dimensions앞의 예에서는 6이라는 요소를 하나만 가지는 벡터 하나와, 10이라는 요소 하나만 가지는 또 다른 벡터를 대괄호 안에 기술한 것이다. 벡터는 일차원 구조로 오직 한 개의 인덱스 벡터를 입력 받으므로, 위의 경우는 c(6, 10)으로 하나의 벡터로 결합하여 인덱스 벡터를 전달해야 한다. 행렬에서는 두 개의 인덱스 벡터를 입력받게 되는데, 이 형식과 벡터의 인덱스 벡터를 혼동하지 않아야 한다.
추출해야 할 요소를 사용자가 직접 지정할 수도 있지만, 어떤 경우에는 함수를 이용하여 원하는 요소를 특정할 수도 있다. 예를 들어 which.min() 함수는 숫자 벡터의 최소값의 위치를 자연수 인덱스 형식으로 반환한다. 따라서 which.min() 결과를 인덱스 벡터로 이용하면 해당 벡터의 최소값을 추출할 수 있다. 자연수 인덱스 벡터로 많이 사용되는 함수 중 하나가 order() 함수이다. order() 함수는 크기 순으로 벡터 요소의 위치를 반환해 주는 함수이다. 이 함수의 결과를 인덱스 벡터로 사용하면 벡터의 요소를 크기로 정렬하는 효과가 발생한다.
[1] 1[1] 13[1] 13 11[1] 1 4 4 6 7 9 11 133.5.2 음의 정수 인덱스 벡터
자연수 인덱스가 추출한 요소의 위치를 표현한다면, 음의 정수 인덱스는 추출하지 않은 요소의 위치를 표현한다. 따라서 벡터 필터링에 음의 정수 인덱스 벡터가 사용되면, 데이터 벡터에서 해당 위치의 요소가 제외된 나머지 요소로 새로운 벡터를 만들어 반환한다. 예를 들어 인덱스 벡터가 -2라면 원래 벡터의 2번째 요소만 제외한 나머지 요소로 이루어진 벡터가 반환된다(그림 3.7 참조).
[1] 11 12 13 14 15 16 17 18 19 20[1] 11 13 14 15 16 17 18 19 20[1] 11 13 15 16 17 18 19 20[1] 11 12 17 18 19 20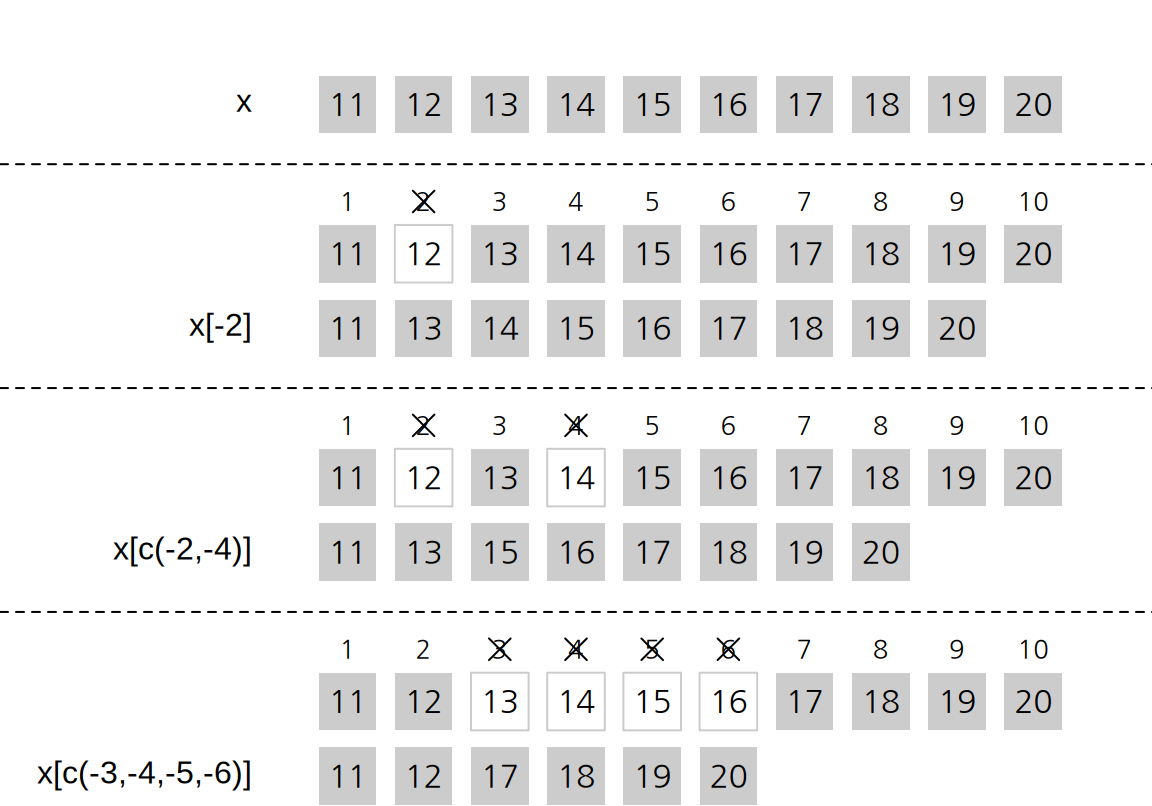
Figure 3.7: 음의 정수 인덱스 벡터를 이용한 벡터 필터링
3.5.3 논리 인덱스 벡터
논리 인덱스는 추출할 요소는 TRUE, 추출하지 않을 요소는 FALSE로 표시한다. 인덱스 벡터가 논리 벡터로 주어지면 데이터 벡터에서 TRUE 위치의 요소만 선택되어 새로운 벡터가 만들어진다. 다음 예와 그림 3.8은 논리 인덱스 벡터가 벡터 필터링에 어떻게 사용되는지를 보여준다.
[1] 1 3 4
Figure 3.8: 논리값 인덱스 벡터를 이용한 벡터 필터링
위의 예처럼 사용자가 직접 추출할 요소를 TRUE로 직접 기술하여 논리 인덱스 벡터를 제공할 수도 있지만, 더 많은 경우는 추출할 조건을 비교 연산 표현식으로 제공하는 경우가 더 많다(그림 3.8 참조).
[1] FALSE FALSE FALSE TRUE TRUE[1] 4 5[1] FALSE FALSE FALSE TRUE FALSE[1] 4다음처럼 논리 인덱스 벡터가 데이터 벡터의 길이보다 작으면 인덱스 벡터가 재사용되어 벡터 필터링이 이루어진다.
[1] 1 3 53.5.4 이름 인덱스 벡터
R에선 벡터의 각 요소에 이름을 부여할 수 있다. 이름 인덱스 벡터는 추출할 요소의 위치를 벡터 요소의 이름으로 지정하는 방식이다. 벡터 요소의 이름은 names() 함수로 확인하거나 할당할 수 있다. 벡터의 요소에 이름을 부여하면, 벡터가 출력될 때 데이터의 값뿐 아니라 요소의 이름도 함께 출력이 된다. 다음은 names() 함수를 이용하여 animals라는 숫자 벡터의 각 요소에 이름을 부여한 후, 이름 인덱스 벡터로 요소들을 추출한 예이다.
cats dogs camels donkeys
5 7 3 2 camels
3 dogs donkeys
7 2 3.5.5 인덱스 벡터를 이용해 벡터 요소에 값 할당하기
지금까지는 인덱스 벡터를 이용하여 필요한 요소를 추출하는 방법에 대하여 살펴보았다. 그런데 인덱스 벡터를 이용하여 데이터 벡터의 특정 요소에만 값을 할당할 수도 있다. 다음은 숫자 인덱스 벡터를 이용하여 벡터의 특정 요소에 값을 할당한 예이다.
[1] 1 2 3 4 5[1] 1 20 3 4 5[1] 1 20 100 4 300[1] -5 20 -5 4 -5[1] -5 0 0 0 0다음은 논리 인덱스 벡터를 이용하여 결측치가 있는 데이터에 결측치 대신 0을 넣는 예이다. is.na() 함수는 결측치가 있는 위치를 TRUE로 하는 논리값 벡터를 반환하므로, 이 결과를 인덱스 벡터로 하면 결측치가 있는 위치만 지정됨을 알 수 있다.
[1] NA 2 3 4 NA[1] 0 2 3 4 0다음은 논리 인덱스 벡터를 이용하여 숫자 벡터의 요소를 모두 양수로 바꾸는 예이다.
[1] 2 0 4 7 8Kabacoff, Robert. R in action. Manning Publications Co., 2015.↩︎